[系列文章]下一篇:《Coding中的编码问题之入门&概览》
因为想着把毕业设计中的读写器上位机软件放在 Qt 上开发,这学期《物联网导论实验课程》也做过一个类似的上位机软件,不过是在 MFC 上开发,所以想到先做一下这个课程 Project 的移植,体验一发 Qt,没想到一开始就碰大壁了。。。
相信大家也经常遇到,那就是做 UI 界面时或者通过 UI 给用户提示时,中文乱码 的现象。比如,这学期,在上《物联网导论实验课》的时候,虽然课程建议的开发平台是 VC++ 6.0,但是有部分同学尝试在 VS≥2012 开发,就发现,课程 Demo 给的部分示例代码直接放到 VS 上,就出现了 UI 中文乱码的现象。他们,或者说大多数人一开始想到的问题,无非就是项目相关文件保存方式弄错了,也许改一下保存编码方式就行。但是真的是这样吗?还有编码方式是什么,解决这个问题需要了解多少东西?本期及之后的几篇文章,将会跟大家讲述本人在解决这个问题过程中的学习体会,包括从网上学习的各种资料的汇总。一来希望能给遇到相关问题的亲们指引一下(希望对你有帮助,嘻嘻),二来更是把自己这近几周的学习作一个系统总结,留档,方便后知后觉忘了的时候,可以温故知新。
先说说环境
这是我的本本:
- 操作系统: Win8.1 专业版
- VS: 安装了 Visual Studio2013,应该是 64-bit 的
- Qt版本: Qt 5.5.1 for Windows 64-bit (VS 2013, 823 MB),qt-opensource-windows-x86-msvc2013_64-5.5.1.exe
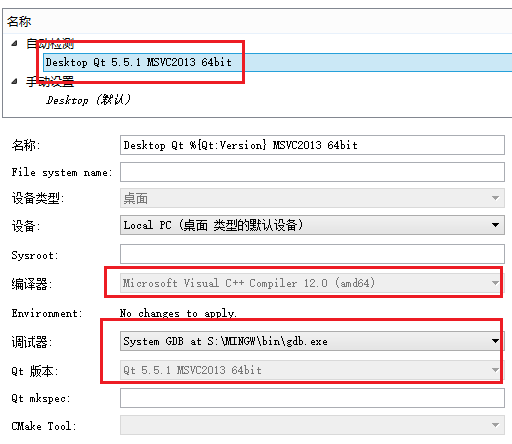
- 开发IDE: 使用上述安装包中自带的 Qt Creator3.5.1(Based on Qt5.5.1(MSVC2013, 32bit)),不过上面的 Qt 版本应该是 64 位的(见下图)。
- 其他: 32 位的 MINGW (这个后来发现没什么卵用):
下面是 Qt Creator 中构建套件截图:
再看看问题
新建 Qt Widgets Application,UI 主框架是两个切换选项卡,只需要在界面设计栏中拖入 Containers → Tab Widget,适当调整大小即可。然后需要在 MainWindow 类构造函数 中添加代码(因为这部分是在界面呈现之前需要完成的部分,放在构造函数中理所应当):1
2
3
4
5
6
7
8
9
10MainWindow::MainWindow(QWidget *parent) :
QMainWindow(parent),
ui(new Ui::MainWindow)
{
ui->setupUi(this);
// 设置标签名
ui->tabWidget->setTabText(0, "调试助手");
ui->tabWidget->setTabText(1, "应用开发");
}
ui 通过初始化列表(初始化列表以冒号开头,后跟一系列以逗号分隔的初始化字段)这种方式已经和我们的界面绑定,通过 ui->tabWidget 则可以获取到我们新添加进去的 Tab Widget,然后就是调用 Tab Widget 的 API,setTabText 设置标签名,第一个参数是下标,从 0 开始计数,第二个参数则是标签名。构建运行,结果如下图:
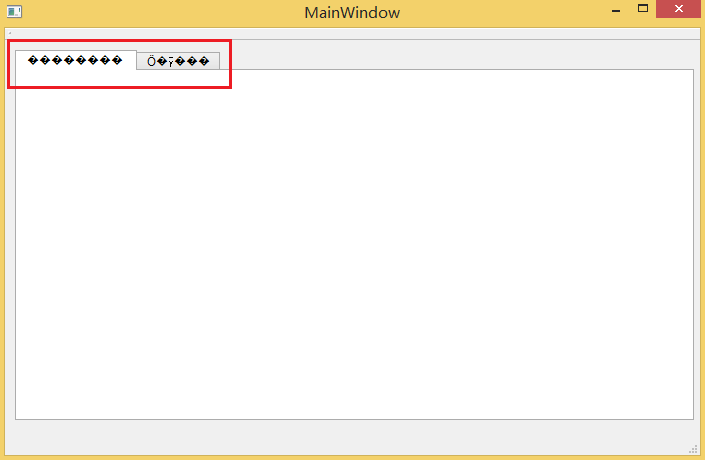
分析:
- 确实实现了两个标签的选项卡,也能正常实现切换,问题就是,这两个标签究竟是什么鬼…这就是上面提到多次的 中文乱码。
- 有人会说肯定是源文件编码方式出错了,造成乱码。Qt Creator (更准确的说,我这里的 Qt Creator )文件保存方式默认是 使用带BOM的UTF-8 保存的(说的是什么鸟语,如果不懂这些到后面你就会懂了,还有,我是怎么知道的,用 NotePad++ 打开 Qt 工程目录下的文件,HexViewer 一下便知道了,后续也会说)。而我们的 UI 文件,也是按照 UTF-8 编码的,因为 .ui 文件其实是一个 xml 文件:
1
2
3
4xml version="1.0" encoding="UTF-8"
<ui version="4.0">
...
</ui>
按理说,不会因此造成乱码的。事实是,不管你把源文件(主要是带有我们汉字的 mainwindow.cpp)的编码方式变成哪一种,还是照样乱码,而且是同一种乱法,都是上图那个样。
第一种: 菜单栏工具 →选项 →文本编辑器 →行为:
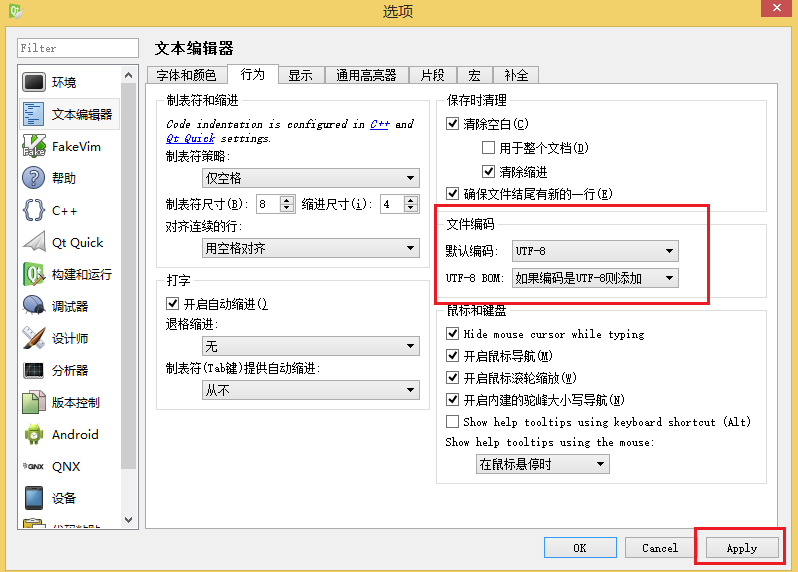
对
文件编码 的 默认编码 和 UTF-8 BOM 进行设置,然后 Apply 应用设置。注意,个人认为此处设置的是默认编码,会对新建的项目或文件有效,也就是说,这里设置成什么样,整个 Qt 的文件默认编码方式就是什么;不过对你已经创建的文件,可能没什么影响,个人体会是这样。
第二种: 那已经存在的文件怎么修改编码方式呢?菜单栏 编辑 →Select Encoding... →选择编码方式 →按编码保存。
如上图所示,我的默认编码采用 UTF-8 而且采取 如果编码是UTF-8则添加BOM 的方式,也是 建议大家采用的(后面你就明白了)。上面说到修改文件的编码,我通过第二种方式大概尝试了 System (本系统是简体中文的 Win8.1,这里的 System 编码,应该等同于 ANSI,也就是 GBK 编码(繁体中文则是 Big5 编码))、GB2312 (汉字国(家)标(准),GBK 兼容 GB2312,是其的扩展)、UTF-8带BOM 和 不带BOM的UTF-8 (设置成如果编码是UTF-8则添加然后按 UTF-8 编码保存即是 带BOM的UTF-8,设置成 总是删除 然后按 UTF-8 编码保存则是 不带BOM的UTF-8 )这几种。具体的编码是什么,这一块的知识会在后面陆续为大家介绍。
解决方案
不管你按照上面说的改文件编码方式,改成什么,都没有用。还是乱码,而且乱的是一个样子,故我的初步估算是,这其实跟源文件的编码没什么关系。更恐怖的是,如果你改成 不带BOM的UTF-8 保存你的文件,甚至会报错,如下:
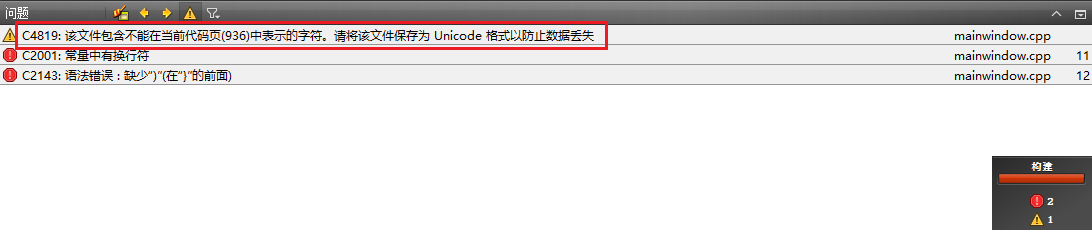
看到这个,我的疑惑只有,什么是 代码页(后面也会跟你说的);还有,哦不,太可怕了,我赶紧退回去上一种编码,然后运行一下,发现错误没了,这才松了口气。
既然该文件编码没用,跟源文件编码没多大关系,那怎么解决呀,存在乱码可不行,毕竟这是 BUG 呀。
我就看了下这一篇文章《解决Qt中文乱码以及汉字编码的问题(UTF-8/GBK)》。主要的内容摘要如下,你可以亲自去看看。
一、Qt 环境设置
文件从 window 上传到 Ubuntu 后会显示乱码,原因是因为 Ubuntu 环境设置默认是 utf-8,Windows 默认都是GBK。
Windows 环境下,Qt Creator,
菜单->工具->选项->文本编辑器->行为->文件编码:默认编码: System (简体中文 windows 系统默认指的是 GBK 编码,即下拉框选项里的 GBK/windows-936-2000/CP936/MS936/ windows-936)
注: 这些是不是和我上面说的差不多,其实我是参考人家的,现在看来,其实也验证了我上面的说法。
二、编码知识科普
Qt 常见的两种编码是: UTF-8 和 GBK
★ UTF-8: Unicode TransformationFormat-8bit,允许含 BOM,但通常不含 BOM。是用以解决国际上字符的一种多字节编码,它对英文使用 8 位(即一个字节),中文使用 24 位(三个字节)来编码。UTF-8 包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8 编码的文字可以在各国支持 UTF8 字符集的浏览器上显示。如,如果是 UTF8 编码,则在外国人的英文 IE 上也能显示中文,他们无需下载 IE 的中文语言支持包。
★ GBK 是国家标准 GB2312 基础上扩容后兼容 GB2312 的标准。GBK 的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成 1。GBK 包含全部中文字符,是国家编码,通用性比 UTF-8 差,不过 UTF-8 占用的数据库比 GBK 大。GBK 是 GB2312 的扩展,除了兼容 GB2312 外,它还能显示繁体中文,还有日文的假名。
★ GBK、GB2312 等与 UTF-8 之间都必须通过 Unicode 编码 才能相互转换:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312
★在简体中文 windows 系统下,ANSI 编码 代表 GBK/GB2312 编码,ANSI 通常使用
0x80~0xFF 范围的 2 个字节来表示 1 个中文字符。0x00~0x7F 之间的字符,依旧是 1 个字节代表 1 个字符。Unicode(UTF-16) 编码则所有字符都用 2 个字节表示。注:这里贴给大家先做个了解,大概的疑惑应该会有:
1、什么是 UTF-8 和 GBK,他们是怎样表示汉字和英文的?
2、UTF-8 有带不带 BOM 之分,究竟什么是 BOM 呢?
3、GBK 中英文都用两个字节表示,为了区分中文,将其最高位都设定为 1,这种区分似乎挺重要的,我要仔细了解一下!
4、这中间提到的 GB2312 和 Unicode 编码又是什么?
5、ANSI 中
0x00~0x7F 之间的字符,依旧是 1 个字节代表 1 个字符,0x00~0x7F是不是就是最常见的 ASCII 编码,起码他们的范围是一致的,而且都是一个字节。这些疑惑相信你后续都会弄明白的。不过这里说的 Unicode 编码,就像作者后面 (UTF-16) 这个括号加上去一样,他应该指的是 UTF-16 这种编码方式。而 Unicode,更准确的理解,它应该是一种字符集。那你可能会疑惑,字符集又是什么,他跟编码方式为什么不能一概而论,有什么区别?另外这里说的,UTF-16 编码则所有字符都用两个字节表示,其实不太对,UTF-16 跟 UTF-8 一样,都是变长编码方式(你一定会想到有变长肯定有定长之说,的确,那二者有什么区别呢?)。此外,不只 UTF-8 有 BOM,UTF-16 也有 BOM,而且,UTF-8 的 BOM 可有可无,UTF-16 的 BOM 可是有大用处,也是 BOM 的本质由来,区分大小端——那什么是大小端?怎么区分法?这些你先大致了解,后续会让你明白的。
三、编码转换
UTF-8 与 ANSI (即 GBK)的互转,可以使用 EditPlus 工具”文件另存为”或者 Encodersoft 编码转换工具对 .cpp 和 .h 源文件文本进行批量转换。
注:我试了下 EditPlus 工具,哭晕了,不好用的啦。后来发现 NotePad++ 似乎更好用好多。怎么用嘛,看这里。
四、Qt 编码指定
Qt 需要在 main() 函数指定使用的字符编码:
#include <QTextCodec>QTextCodec *codec = QTextCodec::codecForName("GBK"); //情况 2 是此处 “GBK” 变为 “UTF-8”QTextCodec::setCodecForTr(codec);QTextCodec::setCodecForLocale(codec);QTextCodec::setCodecForCStrings(codec);这里只列举大家最常用的3个编译器(微软VS的中的cl,Mingw中的g++,Linux下的g++),源代码分别采用 GBK 和 无BOM的UTF-8 以及 有BOM的UTF-8 这 3 种编码进行保存,发生的现象如下表所示。
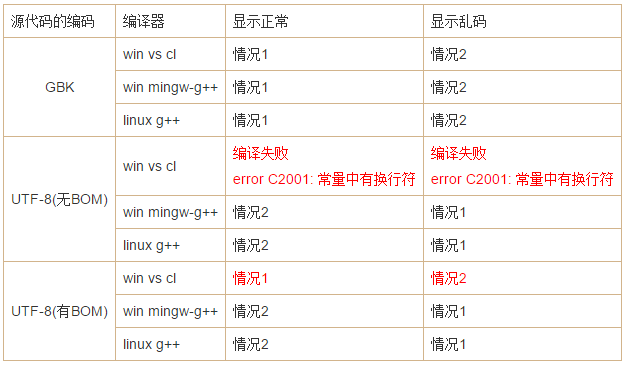
注:上面的现象似乎挺对的,反正我们在 Win 下使用 VS2013的cl编译器,保存成
不带BOM的UTF-8 出现上面的错误,编译确实不通过。至于其他平台,有兴趣你就去试试吧,反正姑且我是信了他。至于这其中的乱码解决方案,尝试了一下,才发现,setCodecForTr 和 setCodecForCStrings 这两个 API 在 Qt5 及以上版本已经不存在了,这一部分是通过阅读这一篇博客了解到《QTextCodec中的setCodecForTr等终于消失了 (Qt5)》,下面是这篇博客的摘要及分析。所以,这一篇文章到此处,只能说他提出的解决方案并不太好,已经被人舍弃了,而且这个解决方案也不适用于我目前的情况,谁叫我的版本已经是最新的 Qt5.5 了呢…五、应用案例
QCom 跨平台串口调试助手(http://www.qter.org/?page_id=203)
… …
注:这一部分主要说了作者自己的一个开源项目,串口调试助手,看了一下,有相关需要再借鉴参考;另外就是上面我们提到的不带 BOM 的 UTF-8 保存的话会报的错,只能改成其他其他编码了,反正 UTF-8 一定要带 BOM 就是了;至于他解决乱码的方式,使用的是 Qt5 以下的那种,上面也提到说已经被拧掉,加上我们这里是 Qt5 以上,就不说他了。
六、结论
①、Windows 环境下,Qt Creator + 微软VS编译器,新建工程,
1、如果该工程不需要跨平台使用(只在 win),那么工程设置请使用 GBK 的编码方式.
2、如果该工程要跨平台使用(win+linux),那么工程设置请使用 UTF-8+BOM 的编码方式.
②、Linux 环境下,Qt Creator+gcc,新建工程,
没有 GBK 编码可选,默认是 UTF-8(无BOM) 编码方式,考虑到跨平台,建议选择 UTF-8+BOM 的编码方式.
注:这一个,个人觉得大致是可行的,只不过,Qt5 之后,所有的东东好像都是 UTF 为默认,比如 QString 就是默认按照 UTF-16 保存的,所以估计 GBK 这一套行不通。考虑到跨平台,也建议全都使用 UTF-8+BOM 的编码方式保存,至于乱码的解决方案,下面会跟大家详细说明。
七、参考文献
Qt 中文乱码问题 http://blog.csdn.net/brave_heart_lxl/article/details/7186631
所以,到底这篇博客还是搞不定我们的问题呀,怎么办呢?上面不是说到,阅读期间按照博主的方法试了一下发现那两个 API 行不通吗。后来就把这个跟 Qt 版本有关的问题一搜,找到另外一篇《QTextCodec中的setCodecForTr等终于消失了 (Qt5)》,这篇文章内容比较散,就把读后认为比较重要的内容记录在下:
博客前面部分正是对上述博客 《解决 Qt 中文乱码以及汉字编码的问题(UTF-8/GBK)》 中提出的该种解法的说词,道出这种解法的不合理以及最终在 Qt5 中这两个 API 木有了,终于让这种乱套解法到头了!
在 Qt5 中,这两个函数:
QTextCodec::setCodecForTr(…)
QTextCodec::setCodecForCStrings(…)
被直接去掉了。这样一来,受影响的直接是如下代码了:
QString s1 = “我是中文”;
QString s2(“我是中文”);
QString s3 = QObject::tr(“我是中文”);
通过这篇博客,了解到上面的”我是中文”,以及我们上述示例中的”调试助手”和”应用开发”是 const char*窄字符串,因为其中包含了中文,所以出现了乱码。
博客说道:
现在 Qt5 中尽管去掉了setCodecXXX 这两个函数,但是默认编码还是 latin-1。如果你要想使用”我是中文”这样的字符串,必须自己使用 QTextCodec 或这 QString::fromXXX 这种东西进行转换。
却又说到:
Qt5 发布之时,默认将会是 utf8 编码,完全可以将你从 Qt 编码问题解放出来。如果你在 Windows 下,且使用的是 MinGW,那么只要你将源码文件保存成 utf8,下面的代码将直接可以工作(无须其他设置)
QString s1 = “我是中文”;
QString s2(“我是中文”);
QString s3 = QObject::tr(“我是中文”);
如果你在其他平台了,那么应该都默认是utf8 文件。同样无须进行设置。
那究竟默认编码是 latin-1 还是 utf-8 啊喂…后面会通过捣鼓 Qt,来验证说,QString 的默认编码应该不是这里说的 latin-1,而应该是 UTF,至于是不是 utf-8,我就不太确定了,后面会说。还有,就是说 Qt5 之后其实不会让你遇到乱码的情况的,你随便写随便就不会有乱码,除非,就像我们踩到下面要说的这个坑一样,我们就奇迹般地遇到乱码了。
如果使用的是 MSVC2005/2008/2010,可能无法使用 utf8 编码,于是下面的代码
QString s1 = “我是中文”;
QString s2(“我是中文”);
QString s3 = QObject::tr(“我是中文”);
将不会工作。因为从 MSVC2005 起,你无法给编译器设置字符串要使用的编码。尽管 2003 之前,也无法设置,但是它会遵循源码文件的编码;而 2005 就自作聪明了,即使你源码文件保存成 不带BOM的utf8,它都会试图帮你转换一下。
下面 捣鼓一下 VS 2013 那部分会为大家充分说明这个,这里先解释一下,其实就是:
1. VS 的 cl 编译器可不管你的源文件是什么编码格式,反正不乱码,编译器能读出来内容就行。那怎么读,也许你会问,无非就是通过各种编码方式的一些标记,其实很多时候就是 BOM 来识别,或者,像那种不带BOM 的 UTF-8 那样,他并不知道是什么,就笼统的用 ANSI(应该就是 GBK)解码,反正一般死不了,因为语言标识符都是英文字母,那就是 ASCII 嘛,utf-8 兼容 ASCII,GBK 也兼容,那就是一样一样的,无所谓。其他的不就是汉字注释,或者包含汉字的字符串嘛,注释对编译器又没什么卵用,至于包含汉字的字符串,那就,你源文件是什么字节数据我就照单收,我编译器读源文件本来就可以知道你一个字节一个字节是什么,我想大概是这样子的。
2. 这种他按照一个字节一个字节来也许是幸福的,因为他不知道你是什么,不敢乱改造你,这就带来,你字符串内存中的数据和你本来的字节数据会是一样的,编译器采用的编码方式并没影响。但是,那种他知道你内容的,比如说带 BOM 的 UTF-8,人家知道你三个字节的数据是一个汉字,他就自作聪明按照自己的编码方式(下面你会知道是 GBK)来处理,那么内存中就是这个汉字对应的两个字节的数据了(GBK 的话,而且这里只说常用字,也就是 BMP 之内的汉字,什么是 BMP,后续你就知道了),他处理什么的时候就变成两个字节了,比如输出到 console,这个还好,Window 下的 console 也几乎都是 GBK 的;输出到 UI 呢?就比如我们输出给 UTF-8 编码的 Qt 界面,结果就跪了,而且这个 UI 界面还不让改编码(我用 NotePad++ 在 Qt Creator 外面动手脚,结果不是 UTF-8 编码的直接不让读!!可以的话,改成 GBK 估计会通)…GBK 的字节数据按照 UTF-8 来解码,造不出几个奇怪的字来,只会是一个字节就一个未知符(就像上面运行界面截图中的乱码)。
上文中提到的 QString::fromXXX 正是乱码问题的一个解决方案:
QString::fromLocal8Bit(“xxxx…”);
使用 fromLocal8Bit 对包含中文汉字的 窄字符串 进行处理。
另外一个解决方案则是使用如下的预编译头修改执行字符集。本文后续部分会回顾并分析这两个解决方案。1
2
3
4
5
6
7
8
9
10/*
* 建议放置在源文件,放置在头文件好像每次都必须重新保存源文件才对源文件有影响
* 这个好像跟 C++ 预编译头 原理有关...
*/
// Coding: UTF-8
捣鼓一下VS 2013
按照上述的方法确实把问题解决了,但是,为什么可以呢? No Zuo No Die,可还是要 try 一 try 呀。想到这里的环境是基于 MSVC2013,隔着一层弄可能弄不出什么名堂,干脆先在纯生的 VS2013 上面捣鼓一下,看能不能看出点眉目。以下几个实验参考 开源中国社区 《Qt 5 中文显示问题》。
实验原理
1. VS2013 如何修改源代码的编码方式:
菜单栏 文件 –> 高级保存选项 –> 编码,对编码方式进行修改,然后保存即可生效。我这里默认的编码是 简体中文(GB2312) - 代码页936,涉及的编码主要是 Unicode(UTF-8 带签名) - 代码页65001、Unicode(UTF-8 无签名) - 代码页65001 (还是那句话,GB2312 啊、Unicode 啊、代码页 啊后续会讲)。
2. 简体中文系统的本地编码(这里不严格的区分了,你可以看看这个《2.6.6. 为何”ANSI编码”(在Windows中)被称为”本地编码”》)是 GBK,代码页936;繁体中文系统则是 Big5,代码页950。
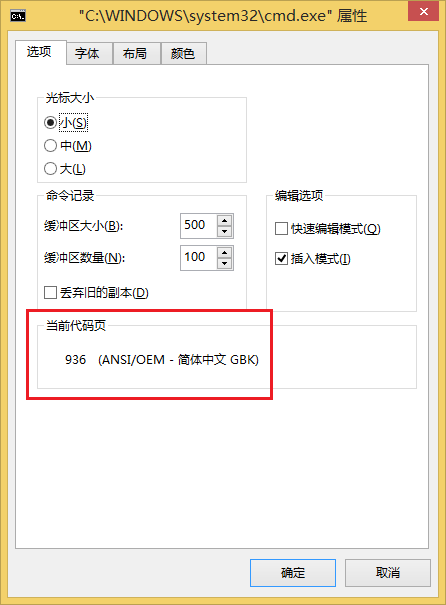
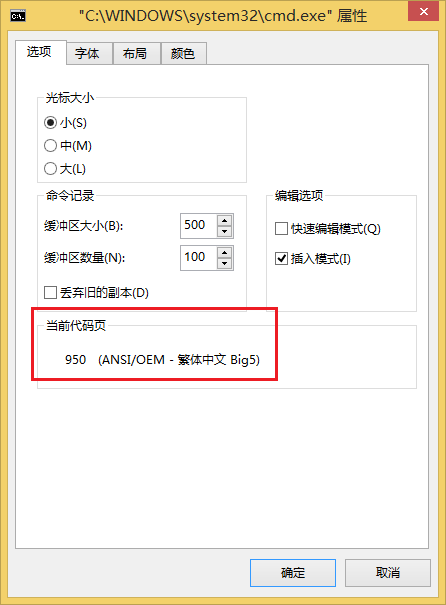
实验(1)、默认(简体中文 GB2312 )编码格式的源代码
新建普通的 Win32 控制台应用程序,主函数所在源文件代码如下:
1 | // executionEncoding.cpp : 定义控制台应用程序的入口点。 |
分析:
1. 所谓的默认编码(这里是指文件的默认编码)是 GB2312,实际上跟 GBK 不差啦,就认是 GB 的编码吧,和本地编码一致。
2. 没有编译错误也没有警告,输出也和源代码一致(你可以用 NotePad++ 看一下): “0xd6 0xd0 0xce 0xc4”,打印字符也能解码: “中文”。
实验(2)、UTF-8 (带签名)格式的源代码
代码不变,编码改为 Unicode(UTF-8 带签名) - 代码页65001,保存。
分析:
1. 没有编译错误也没有警告,但是输出有问题: “0xd6 0xd0 0xce 0xc4”,还是和上面的一样,源文件明明是 UTF-8 编码的格式: “0xe4 0xb8 0xad 0xe6 0x96 0x87”,怎么变成了 “0xd6 0xd0 0xce 0xc4” (这个是”中文”的 GBK 编码)?
2. 长度也不对呀,应该是 6 个字节,怎么变成 4 个字节了呢?
3. 打印字符也能解码: “中文”,这不和上面的一个一个样嘛…奇了个怪了。
实验(3)、UTF-8 (无签名)格式的源代码
代码不变,编码改为 Unicode(UTF-8 无签名) - 代码页65001,保存。
分析:
1. 没有编译错误但是有警告 “warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失”,潜台词就是,你这个代码有 GBK(代码页 936,见上图)不能表示的字符,请用 Unicode 方式保存。cl 编译器根本就没把源代码当作 UTF-8 处理,只是把它按照 GBK 编码方式处理罢了。
2. 不过输出和源代码是一致的: “0xe4 0xb8 0xad 0xe6 0x96 0x87” (这个是”中文”的 UTF-8 编码)。长度也是 6 个字节,这和源代码是一致的!
3. 但是( Everything has a but ),打印字符乱码了,输出是: “涓枃”,这是什么鬼…
实验(4)、使用 #pragma execution_character_set(“UTF-8”) 预编译头
在源代码使用 #pragma execution_character_set("UTF-8") 预编译头:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// executionEncoding.cpp : 定义控制台应用程序的入口点。
//
// 目前只能带参数"UTF-8",其他似乎不支持
int _tmain(int argc, _TCHAR* argv[])
{
/*
* Unicode 的码点分别是(十进制): 中(20013),文(25991)。
* UTF8 编码分别(16进制): 中(E4B8AD),文(E69687)。
* GBK 编码16进制(GBK内码)分别是: 中(D6D0),文(CEC4)。
* Unicode(UTF-16) 编码: 中(2d4e),文(8765)。
* Big5 编码: 中(A4A4),文(A4E5)。
*/
// 不能写成:const char str* = "中文"; 这样变成sizeof(指针)了,大小就一直是4了(我的64位机子)
const char str[] = "中文";
// 数组的sizeof值等于数组所占用的内存字节数,-1去掉'\0'。
for (int i = 0; i < sizeof(str) - 1; ++i){
printf("0x%02x ", str[i] & 0xFF);
}
printf("%s\n", str);
// Output:
// 0xd6 0xd0 0xce 0xc4
// 中文
return 0;
}
重复试验(1)~(3),试验结果如下:
| 源文件编码方式 | 试验结果 |
| 默认编码 | 编译无错误无警告,输出: “0xe4 0xb8 0xad 0xe6 0x96 0x87” (这个是 “中文” 的 UTF-8 编码),和源代码不一致;打印字符出现乱码,输出是: “涓枃” |
| UTF-8 (带签名) | 编译无错误无警告,输出: “0xe4 0xb8 0xad 0xe6 0x96 0x87” (这个是 “中文” 的 UTF-8 编码),和源代码一致;打印字符出现乱码,输出是: “涓枃”;输出结果与上一种情况一致 |
| UTF-8 (无签名) | 编译无错误,还是报 “warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失” 这个警告,输出: “0xe6 0xb6 0x93 0xee 0x85 0x9f 0xe6 0x9e 0x83” (这个是 “涓枃” 的 UTF-8 编码),和源代码相差甚大;打印字符出现乱码,输出是: “娑擃厽鏋?” |
分析:
1. 可以借助各种在线查看工具查看字符编码情况,这里使用 查看字符编码(UTF-8)或者 汉字字符集编码查询。
2. 目前这个预编译头好像只能带参数 “UTF-8”,其他似乎不支持…我试过 “UTF-16”,报了这样一个警告 warning C4695: #pragma execution_character_set: ‘UTF-16’ 不是受支持的参数: 当前仅支持”UTF-8”。
3. 我们可以在 CMD窗口右键 -> 属性 -> 选项,查看到用于打印的窗口的编码方式,实际上就是前面所述的本地编码,实验(1)~(4)均在简体中文系统下进行,本地编码是 GBK。此处可以知道:上述窗口打印的字符,实际上就是对前面输出字节按照 GBK 解码的输出结果。假如输出的是 UTF-8 编码,显然按照 GBK 无法解码出原有汉字,所以出现了乱码。例如:输出的 “涓枃” 的 GBK 编码正是 “0xe4 0xb8 0xad 0xe6 0x96 0x87”。
4. 虽然添加了预编译头,但是报的 warning 还是一样的,cl 编译器还是没把不带签名的源代码当作 UTF-8 处理,还是按照 GBK 编码方式处理了。
实验(5)、切换成繁体中文系统
将系统从简体中文切换至繁体中文,可以参考 《Win8.1简体中文系统切换到繁体中文系统》,重复试验(1)~(4)。实验结果如下表:
| 源文件编码方式 | 试验结果 |
| GB2312 编码,无预编译头 | 编译无错误无警告,输出: “0xd6 0xd0 0xce 0xc4”(这个是 “中文” 的 GBK 编码),和源代码一致;打印字符出现乱码: “笢恅” |
| UTF-8 (带签名),无预编译头 | 编译无错误无警告,输出: “0xa4 0xa4 0xa4 0xe5”(这个是 “中文” 的 Big5 编码),和源代码不一致;打印字符不出现乱码 |
| UTF-8 (无签名),无预编译头 | 编译无错误,报 “warning C4819: 该文件包含不能在当前代码页(950)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失”,输出是: “0xe4 0xb8 0xad 0xe6 0x3f”(“Big5编码:e4b8(銝)ade6(剜)9687(未知);GBK编码:e4b8(涓)ade6(非法)9687(枃)”),和源代码不一致;打印字符出现乱码: “銝剜?” |
| GB2312 编码,带预编译头 | 编译无错误无警告,输出: “0xe7 0xac 0xa2 0xe6 0x81 0x85”(这个是 “笢恅” 的 UTF-8 编码),和源代码不一致;打印字符也出现乱码: “蝚X?” |
| UTF-8(带签名),带预编译头 | 编译无错误无警告,输出: “0xe4 0xb8 0xad 0xe6 0x96 0x87”(这个是 “中文” 的UTF-8编码),和源代码一致;打印字符出现乱码: “銝剜?” |
| UTF-8(无签名),带预编译头 | 编译无错误,报 “warning C4819: 该文件包含不能在当前代码页(950)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失”,输出是: “0xe9 0x8a 0x9d 0xe5 0x89 0x9c 0x3f(这个是 “銝剜?” 的 UTF-8 编码),和源代码不一致;打印字符出现乱码: “???” |
分析:
1. 繁体中文系统下默认编码似乎是:Unicode-代码页1200,为了与前面实验对比,这里需要修改为 简体中文(GB2312) - 代码页936。
2. 因为切换成繁体中文系统,可以查看到用于打印的 Console窗口 的编码方式虽然还是本地编码,但已经变成 Big5(大五码)。所以,上述窗口打印的字符,变成是对前面输出字节按照 Big5(不再是简体中文系统下的 GBK 了)解码的输出结果。而对于 UTF-8 编码或者是 GBK 编码,按照 Big5 编码还是无法解码出原有汉字,所以还是出现了乱码。
3. 为什么有的字节变成 “”,有的字节变成 “?” 呢?大致查了一下,Big5 编码:”高位字节”使用了 0x81-0xFE,”低位字节”使用了 0x40-0x7E,及 0xA1-0xFE;而 GBK 编码:首字节在 0x81-0xFE 之间,尾字节在 0x40-0xFE 之间,剔除 0x??7F 一条线。对比上面出现的 “”、“?”,你会发现,那些解码成 “?” 的,其字节数据均在合法范围内,只是对应的字符还未定义;而那些解码成 “”,其字节数据不全在合法范围内,属于非法字符。
4. 通过报的 warning 可以看出,cl 编译器还是没把不带签名的源代码当作 UTF-8 处理,不过并不是像在简体中文系统下按照 GBK 编码方式处理,而是按照 Big5 编码方式(代码页950)。
5. 结合前面的实验可知:加了预编译头之后,有点像先按照没加预编译头处理的结果再转换成 UTF-8。更准确地说,编译过程中,cl 编译器按照 Big5 或者 GBK 编码方式(分别对应繁体和简体中文系统,这里感觉说成 ANSI 更好)解码,如果添加了预编译头,再把解码的结果转化为 UTF-8 编码。最终解码结果即是汉字在内存中的保存方式( GBK/Big5 为 2 个字节,UTF-8 一般为 3 个字节)。
6. 通过前面的实验,也可以大概猜测到,上述过程中,假如编译器按照 ANSI 解码,遇到非法字符(如简体中文系统下的 “涓枃” 中的 “0xad 0xe6”)或者未定义字符(如繁体中文系统下的 “銝剜?” 中的 “0x96 0x87”):对于非法字符,保留原有字节数据;对于未定义字符,则有可能变成了 “?”(0x3f)。而当这些情况发生时,cl 编译器发现这些字节数据并不是 ANSI 编码能表达的合理方式,因此也就出现了那个 C4819 编译警告。
7. 至于源文件的编码方式,实际上和上述过程没有联系,只是 cl 编译器不认得 UTF-8(无签名),如果遇到这种编码方式保存的文件,会按照默认编码方式,即 ANSI 对源文件进行解码。你可能会惊讶: Big5 不是有一点点不兼容 ASCII 吗?还好上面代码中的 keyword 都能准确解码。
8. 上述试验中,有些结果似乎与上述结论相违背,比如:实验(3)中输出结果: “0xe4 0xb8 0xad 0xe6 0x96 0x87”,这个确实是 “中文” 的UTF-8 编码。但是如果如上述结论所述,不是会被按照 GBK 解码成其他字符吗?字节数据应该会变的呀。又比如:实验(5),源文件编码方式是 GB2312编码,无预编译头,怎么它的输出还是 “中文” 的 GBK 编码,不是会被按照 Big5 解码成其他字符吗?。反正就是这种输出和源文件编码一致的情况,令人摸不着头脑。对于这种情况,通过对比加没加预编译头,你就会发现,虽然输出和源文件编码一致,但是对于程序来说,已经不是原先我们输入的 “中文” 字面值了,只是这些字节数据在这些 ANSI 编码中既不非法也不是未知字符,恰巧能表示另一个字符罢了。带编译头的输出结果完全能说明这一点。
实验(1)~(5)总结分析
1. 使用繁体中文系统的情况属于少数,我们了解就好。
2. 简体中文系统,编码方式按照默认就行,源文件保存是 GBK(更准确说是 GB2312),编译器解码是 GBK,console(CMD) 窗口编码也是 GBK。
3. 如果涉及跨平台,UTF-8(无签名) 估计是没戏了(UTF-8 本来就不需要 BOM,Linux 默认编码好像就是这个),会被 cl 编译器自作主张,那就使用 UTF-8(带签名),不过需要添加预编译头 #pragma execution_character_set("UTF-8"),这一句的作用是,将 执行字符集 修改为 “UTF-8”。这里你也知道,不加的话,简体中文系统下估计这个 执行字符集 缺省就是 GBK 了。
捣鼓一下基于VS2013构建套件的Qt
捣鼓完 VS2013 之后,带着上述得出的结论,再来捣鼓 Qt5.5 MSVC2013,思路就清晰多了。新建 Qt Console Application,main.cpp 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22//#pragma execution_character_set("utf-8")
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
const char str[] = "中文";
for(int i = 0; i < sizeof(str)-1; i++) { // -1除去'\0'
printf("0x%02x ", str[i]&0xFF);
}
printf("\n%s\n", str);
// 简体中文系统Output:
// 0xe4 0xb8 0xad 0xe6
// 繁体中文系统Output:
// A4 A4 A4 E5
return a.exec();
}
实验结果如下:
<1>、 按 编码[System]保存 → Build → Run,结果是:“0xd6 0xd0 0xce 0xc4”,打印字符不出现乱码:“中文”;
<2>、 预设UTF-BOM 选项:如果编码是UTF-8则添加,按 编码[UTF-8]保存 → Build → Run,结果也是:“0xd6 0xd0 0xce 0xc4”,打印字符不出现乱码:“中文”;
<3>、 预设UTF-BOM 选项:总是删除,按 编码[UTF-8]保存 → Build → Run,结果是:“0xe4 0xb8 0xad 0xe6 0x96 0x87”,打印字符出现乱码:“涓枃”;
<4>、 ······
<5>、 实验结果和上面一节 《捣鼓一下VS 2013》 其实是完全一致的!这也不奇怪,本身用的就是同一个编译器,编译运行环境应该是一致的。
唯一的区别可能就是:
假如是一个 Qt Widgets Application 工程,源文件按照 不带BOM 的UTF-8 保存,不仅仅只是简单的一个编译警告,而是还会出现像 《解决方案》 一节开头说的那个令人大跌眼镜的错误:error: C2001: 常量中有换行符 !!
问题透析,再捣鼓
在已经有了上述经验的基础上,我们重新回顾一下前面提出的问题。发现我们似乎忽略了一个地方,那就是 隐式类型转换!
setTabText 的函数原型是:setTabText (int index, const QString & label),所以这里是不是应该存在一个 字符串 转 QString 的过程呢?从这篇文章 《qt中文乱码问题》 我们明确以下概念:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15明确概念0:
"我是汉字" 是C语言中的字符串,它是char型的窄字符串。
明确概念1:
源文件是有编码的,但是这种纯文本文件却不会记录自己采用的编码
明确概念2:
如同我们都了解的'A'与'\x41'等价一样。
GBK编码下的
const char * str = "我是汉字"; 等价于
const char * str = "\xce\xd2\xca\xc7\xba\xba\xd7\xd6";
当用UTF-8编码时,等价于
const char * str = "\xe6\x88\x91\xe6\x98\xaf\xe6\xb1\x89\xe5\xad\x97";
注意:这个说法不全对,比如保存成带BOM的UTF-8,用cl编译器时,汉字本身是UTF-8编码,但程序内保存时却是对应的GBK编码。
所以,此处存在 const char* 到 QString 隐式类型转化的过程,另外,通过上面的捣鼓,我们很容易理解 注意 部分的内容:执行字符集确定了上述 窄字符串 在内存中的编码方式,说到底,内存中保存的都是 01010…,是通过执行字符集解码获得的。
另外,从这里 《QString够绕的,分为存储(编译器)和解码(运行期),还有VS编译器的自作主张,还有QT5的变化》 了解到 QString 分为 存储(编译器) 和 解码(运行期),由于我们的隐式类型转化显然发生在运行期,也就是通过 窄字符串 参数提供的字节数据构造 QString,那么他使用的解码方式是?我们通过下面代码进行测试:1
2
3
4ui->tabWidget->setTabText(0, "\xe4\xb8\xad\xe6\x96\x87"); // UTF-8 编码序列
ui->tabWidget->setTabText(1, "\xd6\xd0\xce\xc4"); // GBK 编码序列
ui->tabWidget->setTabText(2, "\xA4\xA4\xA4\xE5"); // Big5 编码序列
ui->tabWidget->setTabText(3, "\x4e\x2d\x65\x87"); // UTF-16 编码序列
运行结果如下图:
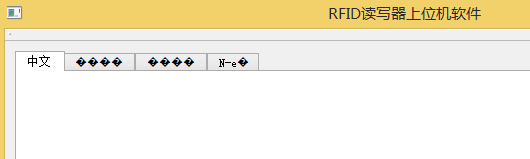
所以此处大胆推测,上述隐式类型转化过程,会通过调用 QString::fromUtf8(“xxx…”) 动态构造 QString,至此,就不难解释前面出现的乱码问题和相应的解决方案了!
乱码问题原因: cl 编译器的默认执行字符集是 GBK,这造成不管你的源码文件是哪一种编码方式(cl 编译器不能识别不带 BOM 的 UTF-8 编码方式保存的文件,会按照默认的 GBK 编码方式解码源文件),编译时都会按照执行字符集对解码结果进行重新编码,而这就是数据(如这里的窄字符串)最终在内存中的存储形式!
另外,setTabText 函数存在一个 QString 的隐式构造过程,采用 UTF-8 编码方式动态解码,结果,原本按照 GBK 编码保存的字节数据被按照 UTF-8 编码进行解码,所以出现了乱码!
方案一思路: 因为默认情况下,是按照 GBK 编码对解码的数据进行编码的,也就是 QString 隐式构造过程中的字节数据是按照 GBK 编码的。所以,只要我们在构造 QString 采取正确的解码方式 GBK,就能正确构造 QString ,从而避免乱码。 QString::fromLocal8Bit ( const char * str, int size = -1 ) 中的 local8Bit 在简体中文 Windows 下,是 GBK;在繁体中文 Windows 下,则是 Big5;所以实际上 local8Bit 对应的编码方式就是我们接下来会了解的 ANSI 编码。此外,上面漏说的一个是,从对 VS2013 的捣鼓结果来看,这个执行字符集更准确来说,也是 ANSI 编码,参考 简体中文/繁体中文 系统下的不同结果可以得出。
故,使用 QString::fromLocal8Bit ( const char * str, int size = -1 ) 可以解决我们的乱码问题。而且,为了保证运行结果与源文件保持一致,我们的源文件编码方式也最好采用 GBK/GB2312 编码方式保存。
方案二思路: 另一种思路就是,既然 QString 的隐式构造过程中采用 UTF-8 编码方式动态解码,我们可不可以在编译时就把数据按照 UTF-8 编码方式进行保存呢?答案是可以的,就像我们从 VS2013 的捣鼓得到的结果一样,通过 #pragma execution_character_set("utf-8") 即可实现。1
2
3
4
5
6
7
8
9
10/*
* 建议放置在源文件,放置在头文件好像每次都必须重新保存源文件才对源文件有影响
* 这个好像跟 C++ 预编译头 原理有关...
*/
// Coding: UTF-8
建议采用上述的参考代码,因为预编译头的使用涉及 Qt 版本(似乎大于 5.0 才有用),VS 版本(如上面所说,VS2005 以后);此外留意上面的注释说明,即注意这部分预编译头在代码中的位置!!而且,为了保证运行结果与源文件保持一致,我们的源文件编码方式则最好采用 UTF-8 编码方式保存,而且必须 带 BOM。
最后,我们来讨论一下,为什么 Qt 中在 UI 设计过程中编辑的中文字符不会出现乱码的问题。比如,你可以在 UI 设计时通过修改 QTabWidget 的 currentTabText 来设置选项卡标签,从而快速实现文章开头的代码功能。这里我们通过这种方式添加两个标签:调试助手、应用开发,你会发现,通过这种方式很容易就实现我们需要的功能!重要的是不会出现乱码!那这又是怎么实现的?或者说 Qt 工程是如何将 UI 界面的 XML 文件引入到工程的,毕竟我们的项目,或者说我们知道 Qt 最终都是通过 C++ 来编译构建的。
实际上, Qt 在编译的过程中会自动使用一个叫 uic.exe 的工具(这个工具可以在“Qt根目录\5.5\msvc2013_64\bin” 找到)将 UI 界面的 XML 文件转化为 .h 头文件,比如这里,mainwindow.ui 文件就被转化为 ui_mainwindow.h 文件,并在 mainwindow.cpp 中通过 #include "ui_mainwindow.h" 的方式引入。那究竟这个 ui_mainwindow.h 头文件长怎么样?怎样能够实现 UI 设计与执行代码分离,最后又能够整合在一起呢?
这个 ui_mainwindow.h 头文件似乎只是一个中间临时文件,在 工程目录 或者 生成目录 都找不到它的影子,需要我们手动生成,生成过程如下:1
2
3
4
5
6
7
8
9
10
11
12
13手动生成ui文件对应类:
ui文件只是一个xml文件,编译器是不认识的,所以qt做了一个uic.exe的工具,
会将ui文件(xml)默认编译成ui_xxx.h(编译过程如下描述),
这样编译器就能使用designer做出来的界面文件了,你在mainxxx.cpp中包含的头文件就是上面提到的ui_xxx.h,
你可以打开这个文件看一下(右键 → Open Include Hierarchy → 打开ui_xxx.h),
其实就是用代码描述了你在disigner中画的界面。
命令:
cd D:\Workspace\Qt Workspace\Demo @进入界面文件 xxx.ui 所在目录
d: @通过此方式切换盘符
set path=S:\Qt\5.5\msvc2013_64\bin;%path% @把 uic.exe 路径追加到当前 CMD 的 path 中
@只对当前窗口有效
uic mainwindow.ui > ui_mainwindow.h @生成.ui 对应的.h 文件,并保存在 ui_xxx.h 文件中
生成的 ui_xxx.h 头文件结构大致如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58/********************************************************************************
** Form generated from reading UI file 'mainwindow.ui'
**
** Created by: Qt User Interface Compiler version 5.5.1
**
** WARNING! All changes made in this file will be lost when recompiling UI file!
********************************************************************************/
// 此处有一系列 include,包括选项卡相关的 QtWidgets 等相关类
...
QT_BEGIN_NAMESPACE
class Ui_MainWindow
{
public:
// 界面中使用的一系列控件的成员声明,包括QWidget(选项卡主框架)、QTabWidget(选项卡标签)、QPushButton(按钮)
...
void setupUi(QMainWindow *MainWindow)
{
// 成员变量的一系列初始化
...
retranslateUi(MainWindow);
tabWidget->setCurrentIndex(0);
// 信号槽机制!!
QMetaObject::connectSlotsByName(MainWindow);
} // setupUi
void retranslateUi(QMainWindow *MainWindow)
{
// 主界面标题、按钮、选项卡标签等涉及中文汉字的转义
...
// 下面是左右两个标签"调试助手"、"应用开发"的转义
tabWidget->setTabText(tabWidget->indexOf(tab),
QApplication::translate("MainWindow",
"\350\260\203\350\257\225\345\212\251\346\211\213", 0));
tabWidget->setTabText(tabWidget->indexOf(tab_2),
QApplication::translate("MainWindow",
"\345\272\224\347\224\250\345\274\200\345\217\221", 0));
} // retranslateUi
};
namespace Ui {
class MainWindow: public Ui_MainWindow {};
} // namespace Ui
QT_END_NAMESPACE
uic.exe 工具将我们设计的 UI 界面文件转化为一个相关的类,并以头文件的形式提供给主程序,这就是我们上面提到的转化过程。注意这里有关中文汉字的转义,使用的是一种叫做 “八进制转义序列”(Octal Escape Sequence),ui 生成的 UTF8 是用 C 语言的转义字符实现的,VC 不会私下做手脚,因此是能显示的。举个例子,“调试助手” 的 “调” 的 UTF-8 编码是: E8 B0 83,使用的是十六进制,换成八进制,正是: \350\260\203,其他汉字字符均是按照这种方式进行转义的。
有这样的理解:
只要代码知道 "\350\260\203\350\257\225\345\212\251\346\211\213" 这段转义是按照什么编码转义的,那么不管到哪都能最后生成唯一的 Unicode 字符串。
因为,这段转义文本(不是转义前的文本)不管是用 gbk 还是 utf8 编码的,ascii 字符的编码是对应的,到哪看都是 "\350\260\203\350\257\225\345\212\251\346\211\213",而不会变成乱码,而你要是直接写中文就不好说了;
或者说,为了 避免源码字符集不同而导致最后程序的字符集不同,那些在不同字符集中有歧义的非 ascii 字符就要转义成上面这种形式才可以避免!
注意,假如你在界面文件中输入 ASCII 字符,是不会发生上面的转化的!!
所以,我们也可以在代码中仿造这种方式,直接使用中文汉字的(Octal Escape Sequence),不过,这样转化实在太麻烦了,你不觉得烦吗?要先获取 UTF-8编码,再转成八进制!,建议还是理解上面所述的内容,这样你就能够顺利、清晰的解决乱码问题!
说在前头的总结
- 我们大概可以猜测到乱码的原因:无非就是编码方式与解码方式不一致造成。但!编码方式体现在哪里?编译时采用的编码方式?解码方式又体现在哪里?运行时使用的动态解码方式?
- 各种编码方式是怎样的?为什么方式不一致就会出现乱码呢?那有什么办法可以避免?
- 借 Qt 中文乱码问题的分析,拉开我们有关字符编码系列的阐述,在接下来的三篇文章里面,将会尽可能多的为大家讲述 字符编码 的相关概念和问题分析,希望能帮助大家建立这一块的知识网络。
Version Control 版本号 日期 内容 作者 V1 2016.2.1 起草博客、框架 Tarantula-7 V1.5 2016.2.3 添加两篇博文摘要 Tarantula-7 V2 2016.2.5 完成捣鼓VS2013部分 Tarantula-7 V3 2016.2.29(返校) 完成捣鼓一下基于VS2013构建套件的Qt部分 Tarantula-7 V4 2016.3.1(在校) 完成全部内容初稿 Tarantula-7 V4.1 2016.3.2 完成内容复审 Tarantula-7
| 版本号 | 日期 | 内容 | 作者 |
| V1 | 2016.2.1 | 起草博客、框架 | Tarantula-7 |
| V1.5 | 2016.2.3 | 添加两篇博文摘要 | Tarantula-7 |
| V2 | 2016.2.5 | 完成捣鼓VS2013部分 | Tarantula-7 |
| V3 | 2016.2.29(返校) | 完成捣鼓一下基于VS2013构建套件的Qt部分 | Tarantula-7 |
| V4 | 2016.3.1(在校) | 完成全部内容初稿 | Tarantula-7 |
| V4.1 | 2016.3.2 | 完成内容复审 | Tarantula-7 |