[系列文章]下一篇:《Coding中的编码问题之回顾&深入》
大家在看完《Coding中的编码问题之入门&概览》后,估计对字符编码应该有一个总览性的理解了。本文借 开源中国 上《字符集编码系列》系列博文为大家详细介绍字符编码的诸多细节,相信看完本文后,一定能一一解决你到目前积累的绝大多数疑问,让我们带着疑问现在就开始吧!
Charset vs Encoding
原文地址:http://my.oschina.net/goldenshaw/blog/304493
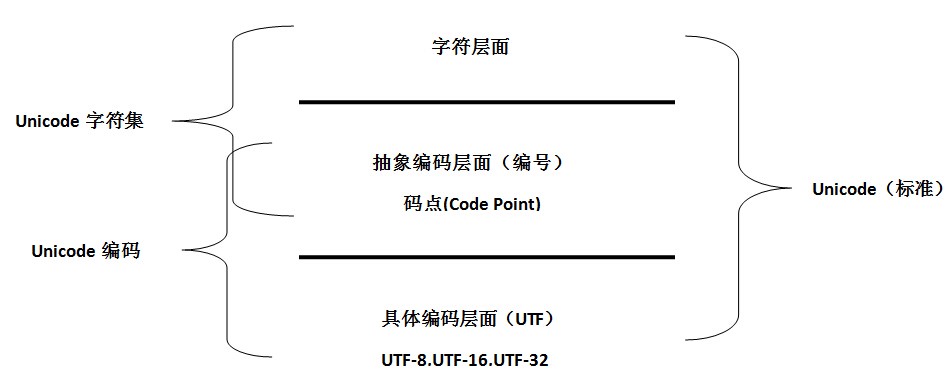
- 字符集与字符集编码是两个不同层面的概念,类比接口与接口实现。
1. 编码是依赖于字符集的,就像代码中的接口实现依赖于接口一样;
2. 一个字符集可以有多个编码实现,就像一个接口可以有多个实现类一样。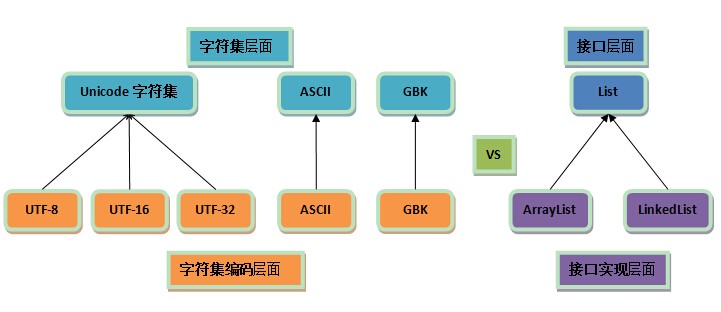
- 字符集与编码存在一对一、一对多的情形(如上图);一对一是一种普遍的情况,为什么?
我们以 GB2312 为例,GB=Guo Biao=国标=国家标准,标准出来本来就为了统一,你一个标准弄出 N 个编码实现来,你让人家用哪个呢? - Unicode 就是特殊的一对多的情形。唯一的 Unicode字符集 对应了三种编码:UTF-8,UTF-16,UTF-32。
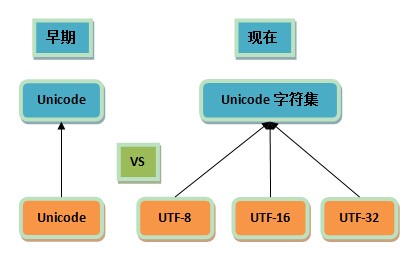
Unicode 的目标是统一所有的字符集,囊括所有的字符,所以字符集发展到它这里就到头了,再去整什么新的字符集就没必要也不应该了。
但如果觉得它现有的编码方案不太好呢?在不能弄出新的字符集情况下,只能在编码方面做文章了,于是就有了多个实现,这样一来传统的一一对应关系就打破了。 - 由于历史方面的原因,你还会在不少地方看到把 Unicode 和 UTF-8 混在一块的情况,这种情况下的Unicode 通常就是 UTF-16 或者是更早的 UCS-2 编码,在后面的篇章中我们会进一步分析。
“记事本程序”保存时的一个截图,是 Unicode 的一个不规范使用,这里的 Unicode 就是指 UTF-16: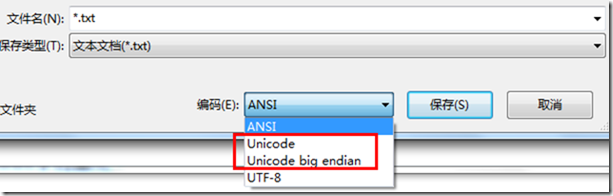
Unicode 的一个具体编码实现,通常即为变长的 UTF-16(之所以称变长,因为这种编码是 16 或 32 位),又或者是更早期的定长 16 位的 UCS-2。
小结:
1. 编码是字符集的一种实现或者说,表现方式;字符集是一套看起来很理论的东西。
2. 知道 Unicode 是种字符集,与其相关有三种编码: UTF-8,UTF-16,UTF-32,那具体是怎样的,是不是应该学学,了解一下呢?
3. UCS-2 也是一种 Unicode 编码,他又是什么? UCS-2 和 UTF-16 的区别?怎么看出哪些是前者,哪些是后者呢?
4. Unicode 居然还有带不带 big endian,这个是什么,他们又有什么区别呢?
编号 vs 编码
原文地址:http://my.oschina.net/goldenshaw/blog/305805
- 编号与编码的主要区别在于编号不涉及具体使用多少字节来表示、是用定长还是变长方案等细节问题。编号仅仅是一个抽象的概念,是把字符数字化的一个过程。
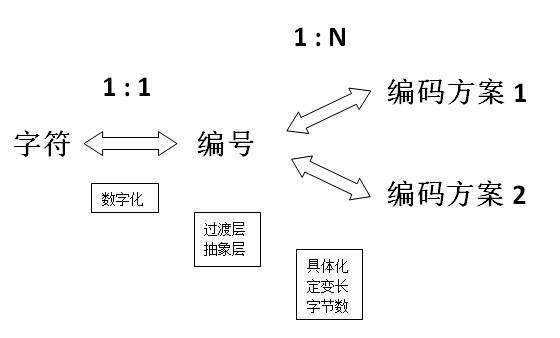
1. 编号一定是一个数字吗?
不一定!它可以是数字对,或者你叫它复数,二元数啥的,随便你。但只要它是离散可数量子化的,它自然也可以转换成唯一的一个数字。参见前面图中的二维区位编号,我们用数字对 (1, 1) 编号 “h” 这个字符。(1, 1) 可以简单转换成 11,然后可以进一步映射到从 0 或者 1 开始的编号。
2. 编号是连续的吗?
如果按日常习惯,编号通常应该从 1 开始,但受编码影响,编号也从 0 开始。
编号写成十进制是更自然的方式,但受编码影响,编号通常也以十六进制形式来书写,并写成固定的位数,不够时就在前面填充 0,比如把 48 写成0048;又比如:U+1D11E就是一个五位的编号。
为了以后的扩展方便,编码常常会跳过某些码位,甚至会保留大片的区域未定义或作保留用途。比如 Unicode 有所谓的 代理区(surrogate area),后续我们会进一步了解。编号因此也跳过这些。
- Unicode 编码的两个层面:抽象编码层面 & 具体编码层面
所谓抽象与具体,以
U+0061(ascii 字母 “a”)为例,十六进制的0061也就是十进制的 97,所谓抽象,也即是用 97 这个数字表示 “a”;所谓具体,就是在计算机的底层到底怎么表示的问题。即便是表示一个整数,你也面临着到底是用 byte,short,还是 int,long 来表示的问题,这就是具体。更具体到编码,你还面临是用定长还是变长等抉择。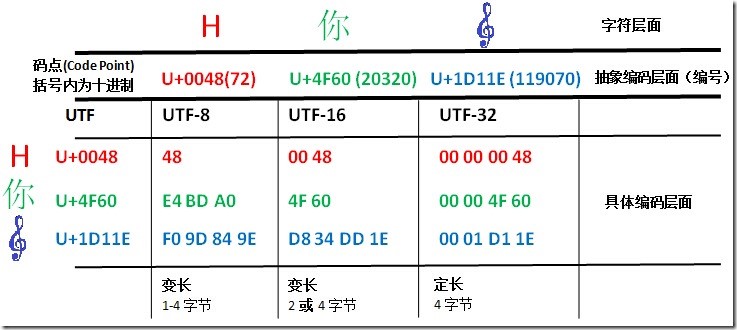
- 关于 Unicode码点 如何具体转换成各种编码,这个在后面再作讨论。从图上我们可以初步得出一些结论。比如:
1. UTF-8 与 UTF-16 都是变长编码,UTF-32 则是定长编码。
2. 码点到 UTF-32 的转换最简单,就是在前面垫 0 垫够 4 字节就行了。
3. 码点到 UTF-8 的转换,除了最小那个在数值上一样外,其它两个完全看不出两者的关系。
4. 码点到 UTF-16 的转换则是最微妙的,可以看出前两个字符 UTF-16 与码点是完全一致的,但那个大码点(准确地说是超过了U+FFFF的码点)则有了很大的变化,长度变成了四字节,值也变得很不一样了。 - 关于 UTF-16 的误解是很多的,部分可能由于它的名字上带了个 16,让人误以为它是 16 位定长的两字节编码。但正像 UTF-8 并不是仅仅是 8 位一样,UTF-16 也不仅仅是 16 位。
事实上,UTF-16 的前身 UCS-2 确实是 16 位定长的编码,它跟码点在形式上就是完全一样了,实际我很怀疑那时候压根就没码点这一说法,那时人们甚至也不说 UCS-2,直接就叫 Unicode!
时至今天,你依然可以在不少地方看到把 UTF-16 写成 Unicode 的,然后与 UTF-8 并排在一起,显得不伦不类的,当然了,这是有历史原因的。
小结:
1. 更加明白字符集和编码的区别了。Unicode 是一种字符集,UTF-8,UTF-16,UTF-32 是具体的编码,UCS-2 也是。
2. 字符集到具体的编码之间还有一个过渡层——码点,不同的字符集已经定义好了字符与码点的对应关系,而编码要做的,就是如何表现码点。不过具体哪一种编码怎么样具体表现,还是个疑问。
3. Unicode 中提到的 代理区(surrogate area) 是什么东西?
4. 编码有定长、变长之说,UTF-8/UTF-16 是变长的,UTF-32 则是定长的。所谓定/变长,似乎就是字符编码的字节长度,UTF-8 可以是 1-4 个字节,UTF-16 可以是 2 或 4 个字节,UTF-32 则都是 4 个字节。
定长与变长
原文地址:http://my.oschina.net/goldenshaw/blog/307708
连续式表示带来的分隔难题:在计算机的最底层,一切都成了 0 和 1,比如,这么一串 “0001100101101110001111111000…”,如果它来自某个文本文件保存后的结果,我们如何从这一串的 0 和 1 中重新解码得到一个个的字符呢?显然你需要把这一串的 0 和 1 分成一段一段的 0 和 1。
1. 在空格与标点都被数字化的情况下,我们在这一串 01 中如何去找出分隔来呢?显然我们需要外部的约定。
2. 8 位(bit)一组的字节是最基本的一个约定,也是文件的基本单位,文件就是字节的序列。字节显然就是最基础的一个分隔依据。定长(Fixed-length)的解决方案:ASCII 编码是最早也是最简单的一种字符编码方案,使用定长一字节来表示一个字符。
如何区分不同的定长(以及变长)编码方式?
1. 答案是:你无法区分!好吧,这么说可能有点武断,有人可能会说 BOM(Byte Order Mark 字节顺序标识)能否算作某种区分手段呢?但也有很多情况是没有 BOM 的。
2. 文本文件作为一种通用的文件,在存储时一般都不会带上其所使用编码的信息。编码信息与文件内容的分离,其实这正是乱码的根源。
3. 我们说无法区分即是基于这一点而言,但另一方面,各种编码方案所形成的字节序列也往往带有某种特征,综合统计学,语言偏好等因素,还是有可能猜测出正确的编码的,比如很多浏览器中都有所谓“编码自动检测”的功能。定长多字节方案 是如何来的?
1. 其实变长多字节方案更早出现,比如 GB2312,采用变长主要为了兼容一字节的 ASCII,汉字则用两字节表示(这也是迫不得已的事,一字节压根不够用)。
2. 问题:那些看到把 6865 保存成 00680065 已经很不爽的人,现在你却对他们说,“嘿,伙计,可能你需要进一步存成 0000006800000065…”。容量与效率的矛盾在这时候开始激化。容量与效率的矛盾
1. 所谓容量,这里指用几个字节表示一个字符,显然用的字节越多,编码空间越大,能表示更多不同的字符,也即容量越大。
2. 所谓效率,当表示一个字符用的字节越多,所占用的存储空间也就越大,换句话说,存储(乃至检索)的效率降低了。
3. 那么有可能在定长方案的框架下解决这一容量与效率的矛盾吗?答案是否定的!矛盾是事物发展的动力,下面我们将看到定长方案的简单性使它无法缓和容量与效率的冲突,平衡这一对矛盾的努力最终推动了编码方案从定长演变到变长,事情也由此从简单变得复杂了。
例如,分层会对性能有所损害,但不分层又会带来紧耦合的问题。很多时候,架构就是关于平衡的艺术。定长二字节方案 无法满足容量增长,转向 定长四字节 又会引发了效率危机,最终,Unicode 编码方案演化成了 变长的UTF-16编码方案。那么 UTF-8方案 又是如何来的呢?为何不能统一成一个方案呢?搞这么多学起来真头痛!
7.1 UTF-16 用所谓的 代理对(surrogate pair) 来编码
U+FFFF以上的字符。
7.2 UTF-8 因为能兼容 ASCII 而受到广泛欢迎,但在保存中文方面,要用 3 个字节,有的甚至要 4 个字节,所以在保存中文方面效率并不算太好,与此相对,GB2312,GBK 之类用两字节保存中文字符效率上会高,同时它们也都兼容 ASCII,所以 在中英混合的情况下还是比 UTF-8 要好,但在国际化方面及可扩展空间上则不如 UTF-8 了。
7.3 其实 GBK 之后又还有 GB18030 标准,采用了 1,2,4字节变长方案,把 Unicode 字符也收录了进来。GB18030 其实是国家强制性标准,但感觉推广并不是很给力。
7.4 在软件开发的各个环节强制统一采用 UTF-8 编码,依旧是避免乱码问题的最有效措施,没有之一。变长(Variable-length) 的编码方案
变长设计的核心问题自然就是 如何区分不同的变长字节,只有这样才能在解码时不发生歧义。8.1 利用高位作区分
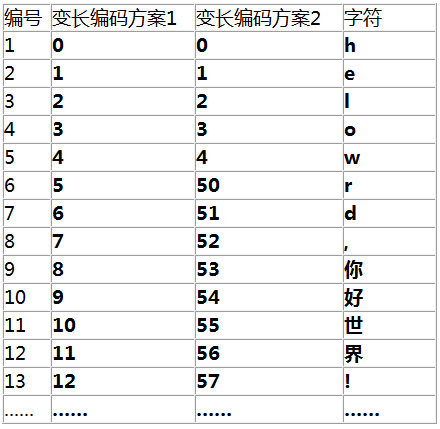
第一种方案,由于低位的码位被“榨干”了,导致单个位与多位间无法区分
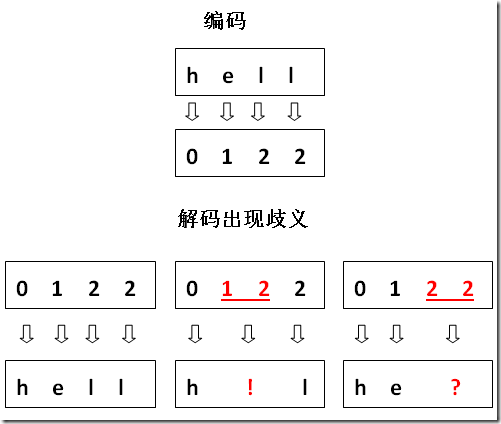
第二种方案,低位空间有所保留。这种方案避免了歧义,因此是可行的方案,但这还是非常粗糙的设计,如果我们想在这串字符中搜索 “o” 这个字符,它的编码是 3,这样在匹配时也会匹配上 53 中的 3,这种设计会让我们在实现匹配算法时困难重重。我们可以在跟随位上也完全舍弃低位的编码,比如以 55,56,57,58,59,65,66…这样的形式,但这样也会损失更多的有效编码位。
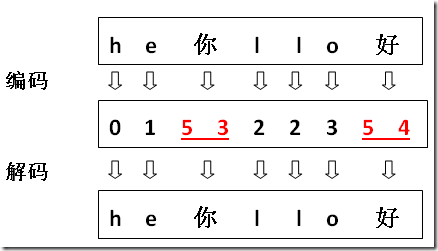
其实关键就在于用高位保留位来做区分,缺点就是有效编码空间少了,可以看到三字节的 UTF-8 方式中实际有效的编码空间只剩两字节。但这是变长方案无法避免的。

由于最高位不同,多字节中不会包含一字节的模式。对于 UTF-8 而言,二字节的模式也不会包含在三字节模式中,也不会在四字节中;三字节模式也不会在四字节模式中,这样就解决上面所说的搜索匹配难题。下面的图以二,三字节为例说明了为什么。
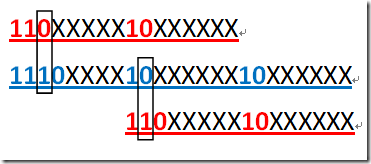
可以看到,由于固定位上的 0 和 1 的差别,使得二字节既不会与三字节的前两字节相同,也不会与它的后两字节相同。其它几种情况原理也是如此。
8.2 利用代理区作区分
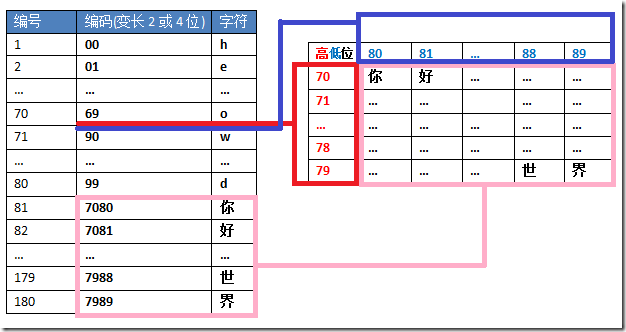
这里挖出 70-89 间的码位,形成横竖 10x10 的编码空间,使得能再扩展 100 个编码空间。原来 2 位 100 个空间 (00-99) 损失了 20(70-89) 还剩 80,再加上因此而增加的 100 个空间,总共是 180 个空间。这样一种变长方式正是 UTF-16 所采用的。
小结:
1. 定长与变长方案涉及字符容量与存储效率的矛盾,当然也涉及编、解码效率等问题。
2. 咱们中国人程序猿,随便用就用 GBK 或者 GB2312(具体怎么样,目前不清楚);但为了国际化,也就是咱要对自己严格要求,还是用 UTF-8(具体怎么样,目前又不清楚)吧。
3. 目前了解的定长编码,咱知道,ASCII 是一个字节定长的,UCS-2 是两个字节定长的,UTF-32 是四个字节定长的。
4. 目前了解的变长编码,咱知道,GBK/GB2312 是 1-2 字节;UTF-8 是 1-4 字节,他们都利用高位作区分;UTF-16 则是 2 或 4 字节,利用代理区作区分。具体怎么做,目前不清楚;代理区是什么,也不太清楚。
5. 因为GBK/GB2312 两个字节搞定中文,兼容(也就是一模一样的编码对应一模一样的字符)伟大的 ASCII;UTF-8 三个字节搞定中文,也兼容 ASCII,二者都比较受欢迎。前者由于存储汉字的效率比 UTF-8 高,备受国人喜爱,本来就中国人自己造出来的;后者则能表示所有 Unicode 字符,推动国际化,受世界人欢迎。中国人就喜欢重复造轮子(chao xi),搞了个和 UTF-8 差不多的 GB18030标准,不受欢迎。。。
Unicode
原文地址:http://my.oschina.net/goldenshaw/blog/310331
什么是 Unicode?

1. 所谓的一个唯一的数字在 Unicode 中就叫做码点。
2.U+[XX]XXXX是码点的表示形式,X 代表一个十六制数字,可以有 4-6 位,不足 4 位前补 0 补足 4 位,超过则按是几位就是几位。
3. 它的范围目前是 U+0000~U+10FFFF,理论大小为: 10FFFF+1=110000(16)。后一个 1 代表是 65536(FFFF),因为是 16 进制,所以前一个 1 是后一个 1 的 16 倍,所以总共有 1×16+1=17 个的 65536 的大小,粗略估算为 17×6 万 =102 万,所以这是一个百万级别的数。
4. 准确的值是 1114112,一般记为 111 万左右即可。什么是平面?
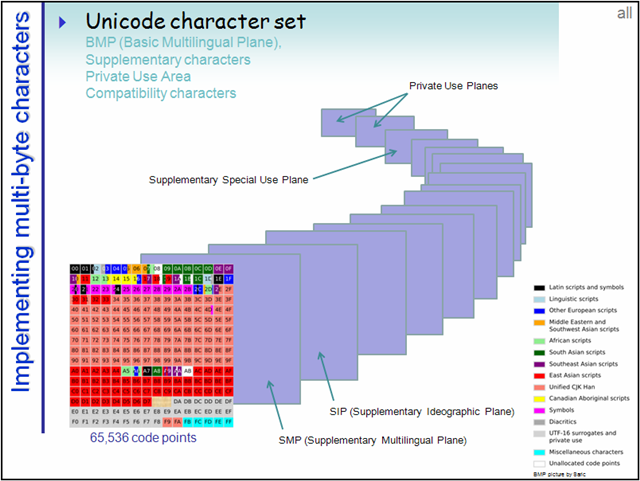
1. 为了更好分类管理如此庞大的码点数,把每 65536 个码点作为一个平面,总共 17(0~0x10) 个平面。
2. 由前面可知,码点的全部范围可以均分成 17 个 65536 大小的部分,这里面的每一个部分就是一个 平面(Plane)。编号从 0 开始,第一个平面称为 Plane 0。什么是BMP?
第一个平面即是 BMP(Basic Multilingual Plane 基本多语言平面),也叫 Plane 0,它的码点范围是 U+0000~U+FFFF。这也是我们最常用的平面,日常用到的字符绝大多数都落在这个平面内。UTF-16 只需要用两字节编码此平面内的字符。什么是增补平面?
后续的 16 个平面称为SP(Supplementary Planes)。显然,这些码点已经是超过U+FFFF的了,所以已经超过了 16 位空间的理论上限,对于这些平面内的字符,UTF-16 采用了四字节编码。CJK 统一汉字
1. 在 Unicode 中间有一大片的区域,称为 CJK统一汉字(CJK:Chinese, Japanese, and Korean,中日韩)。
2. 正则表达式[\u4E00-\u9FA5]来匹配中文的问题在哪?
只要稍加计算就可知这一段大小不过是两万多一点,\u4E00-\u9FA5(19968-40869),中文怎么可能只有这两万多字呢?
3. 这里的“天字第一号”字4E00是哪个字呢?
请看上面的图,它就是“一“字,我们还可以看到它上面还有不少的汉字,这就是后来增补的汉字了。所以严格来说,这个上限是不准确的。那么它的下限又是否准确呢?下面是 Word 的一个插入符号功能的一个截图。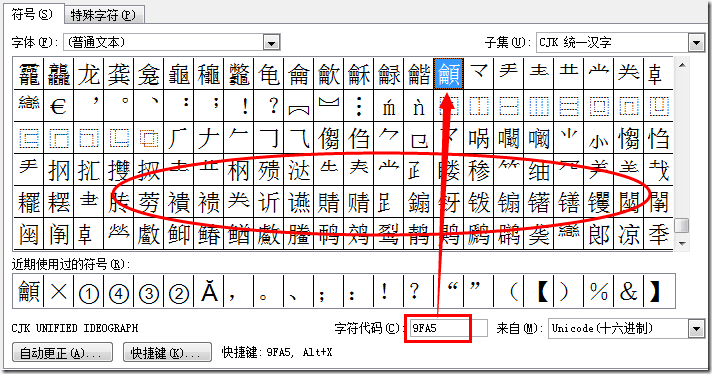
可以看到9FA5后面也还有不少的汉字,它们中间又还夹杂着一些符号,所以想正确地表示 Unicode 中的汉字还是个不小的挑战。
代理区
BMP 缩略图中有一片空白,这就是所谓的 代理区(Surrogate Area)了。
1. 可以看到这段空白从 D8~DF。其中前面的红色部分 D800–DBFF 属于 高代理区(High Surrogate Area),后面的蓝色部分 DC00–DFFF 属于 低代理区(Low Surrogate Area),各自的大小均为 4×256=1024。
2. 还可以看到在它之前是韩文的区域,之后 E0 开始到 F8 的则是属于私有的(private),可以在这里定义自己专用的字符。什么是 UTF?
UTF 即是 Unicode转换格式(Unicode (or UCS) Transformation Format)。关于 UCS:Universal Character Set(统一字符集),也称 ISO/IEC 10646标准,不那么严格的情况下,可以认为它和 ”Unicode字符集“ 这一概念是等价的。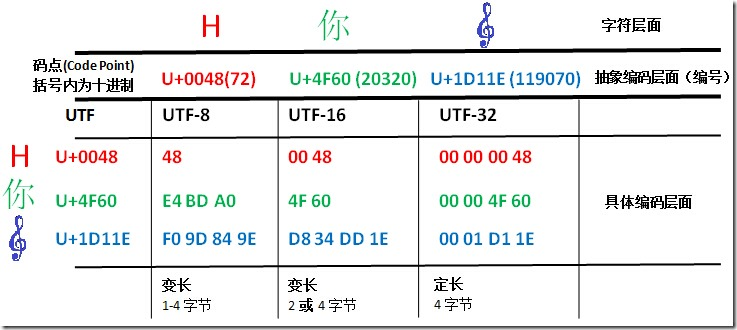
1. UTF-32 (最简单)
我们说码点最大的10FFFF也就 21 位,而 UTF-32 采用的定长四字节则是 32 位,所以它表示所有的码点不但毫无压力,反而绰绰有余,所以 只要把码点的表示形式以前补 0 的形式补够 32 位即可。这种表示的最大缺点是占用空间太大。
2. UTF-8
UTF-8 是变长的编码方案,可以有 1,2,3,4 四种字节组合。在前面的定长与变长篇章我们提到 UTF-8 采用了高位保留方式来区别不同变长,如下:
如上,彩色的表示是保留的固定位,X 表示是有效编码位。
单字节最高位都是 0,多字节的最高位都是 1.
多字节方面,更具体的讲,N 字节模式,首字节以 “N 个 1 再加 0” 打头,后跟 “N-1” 个以 “10” 打头的字节。
哪些码点用哪种变长呢?可以 先把码点变成二进制,看它有多少有效位(去掉前导 0 )就可以确定了。- 一字节有效编码位有 7 位,27=128,码点 U+0000~U+007F(0~127) 使用一字节。
一字节留给了 ASCII,所以 UTF-8 兼容 ASCII。 - 二字节有效编码位只有 5+6=11 位,最多只有 211=2048 个编码空间,所以数量众多的汉字是无法容身于此的了。码点 U+0080~U+07FF(128~2047) 使用二字节。
注意:这里码点从 128~2047,因为去掉了一字节的码点,所以不会占满 2048 个编码空间,是有冗余的,但你不能把适用于一字节的码点放到这里来编码。下同。 - 三字节模式可看到光是保留位就达到 4+2+2=8 位,相当一字节,所以只剩下两字节 16 位有效编码位,它的容量实际也只有 65536。码点 U+0800~U+FFFF(2048~65535) 使用三字节编码。
我们前面说到,一些汉字字典收录的汉字达到了惊人的 10 万级别。基本上,常用的汉字都落在了这三字节的空间里,这就是我们常说的汉字在 UTF-8 里用三字节表示。当然了,这么说并不严谨,如果这 10 万的汉字都被收录进来的话,那些偏门的汉字自然只能被挤到四字节空间上去了。
上图显示了一有效位为 15 位的码点到三字节转换的一个基本原理,我们还可看到原来4F60中的一头一尾的两个 4 和 0 在转换后还存在于最终的三字节结果中。UTF-8 三字节模式固定了 1110 的开头模式,所以多数汉字总是以 1110 开头,换成 16 进制形式,1110 就是字母 E。
如果看到一串的 16 进制有如下的形式: EX XX XX EX XX XX… (每三个三个字节前面都是 E 打头),那么它很可能就是一串汉字的 UTF-8 编码了。 - 四字节的可以看到它的有效位是 3+6+6+6=21 位,前面说到最大的码点
10FFFF也是 21 位,U+FFFF以上的增补平面的字符都在这里来表示。 - 按照 UTF-8 的模式,它还可以扩展到 5 字节,乃至 6 字节变长,但 Unicode 说了码点就到
10FFFF,不扩充了,所以 UTF-8 最多到四字节就足够了。
3. UTF-16
UTF-16 是一种变长的 2 或 4 字节编码模式。对于 BMP 内的字符使用 2 字节编码,其它的则使用 4 字节组成所谓的代理对来编码。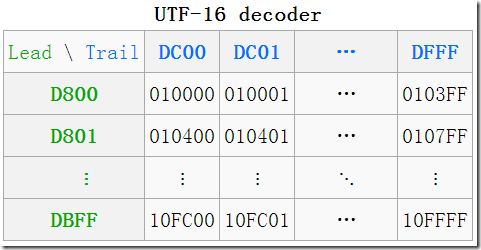
- 什么是 UTF-16代理区?
在前面的鸟瞰图中,我们看到了一片空白的区域,这就是所谓的 代理区(Surrogate Area) 了,代理区是 UTF-16 为了编码增补平面中的字符而保留的,总共有 2048 个位置,均分为 高代理区(D800–DBFF) 和 低代理区(DC00–DFFF) 两部分,各 1024(4xFF),这两个区组成一个二维的表格,共有 1024×1024=210×210=24×216=16×65536,所以它恰好可以表示增补的 16 个平面中的所有字符。 - 什么是 UTF-16代理对?
一个高代理区(即上图中的 Lead(头),行)的加一个低代理区(即上图中的 Trail(尾),列)的编码组成一对即是一个 代理对(Surrogate Pair),必须是这种先高后低的顺序,如果出现两个高,两个低,或者先低后高,都是非法的。
(D8 00 DC 00)—>U+10000,左上角,第一个增补字符
(DB FF DF FF)—>U+10FFFF,右下角,最后一个增补字符 - 码点到UTF-16如何转换?
分成两部分:
1). BMP 中直接对应,无须做任何转换;
2). 增补平面 SP 中,则需要做相应的计算。其实由上图中的表也可看出,码点就是从上到下,从左到右排列过去的,所以只需做个简单的除法,拿到除数和余数即可确定行与列。
拿到一个码点,先减去 010000(16),再除以 0xDFFF-0xDC00=400(16)(=1024(10)) 就是所在行了,余数就是所在列了,再加上行与列所在的起始值,就得到了代理对了。
Lead = (码点 - 10000(16)) ÷ 400(16) + 0xD800
Trail = (码点 - 10000(16)) % 400(16) + 0xDC00
注意:以上计算方式仅用于说明转换原理,不代表实际采用的计算方式。一个码点减去 10000(16) 后实际最多只有 20 位 (10FFFF-010000),再除以 400(16)(=210=10000000000(2)),这个除数实际是一个二进制整数,相当于十进制中整十整百的数。所以结果实际上低 10 位上的就是余数,而高 10 位(或者不到 10 位)上就是商,可以通过更为快速的移位操作实现。举个十进制的例子,就好比是 “1234÷100=12······34”,你都不需要拿笔去算。应该说,代理区的设计是有效率上的考虑的,如果我们要做转换,应该考虑是否有系统API可供调用,而不要自行去实现。
小结:
1. 什么平面、什么 BMP、什么增补平面 SP,无非是一些描述性概念,不过得弄懂,不然后续可能某些东西理解不了了。老实说,这东西,看看、记记就会了。
2. 什么 代理区(Surrogate Area) 啊,其实就是一块编号区域,被用作特殊用途;代理对(Surrogate Pair),说白了,就是取值范围在 代理区(Surrogate Area) 内的坐标,可能加上某些限制吧。具体体现在 UTF-16 编码(其他的我就布吉岛了),将 Unicode 编号中 BMP 平面划一部分出来 U+D800~U+DFFF,就是代理区;(Lead,Trail),Lead∈(U+D800~U+DBFF),Trail∈(U+DC00~U+DFFF),这样的 (Lead,Trail),就称为代理对。
3. 代理区、代理对上一部分也有说,是变长编码一种区分方式。UTF-16 需要这样的代理区,通过代理对与 Unicode 编号一一对应,这样就能编码 1024(U+DBFF-U+D800)×1024(U+DFFF-U+DC00)=210×210=24×216=16×65536,也恰好就是 16 个增补平面,码点取值范围 U+010000~U+10FFFF,这也就是 UTF-16 编码 Unicode 字符集的方式。BMP 以内(~U+00FFFF)就直接编码,其他就转换成代码对 (Lead,Trail),然后用 Lead Trail 四个字节表示。这样就很容易解码了,反正不在代码区的取值,按两个字节解码;在代码区内的,按四个字节解码,查表搞定。
4. 也终于知道 UTF-32、UTF-8 是怎么编码的,和想的还是差不多的,就是定义怎样把码点通过具体的 010101….表示。UTF-32 是定长的代表,定长方案很简单也很显而易见,直接将码点转化成 010101….,不够就补零,超过就木有办法了。人家 UTF-32 肯定考虑到,用了四个字节表示,因为表示 Unicode 最多也只需要21(bit)。UTF-8 则和 UTF-16 一样是变长的,所以也需要一些心思。思路也很简单,只要满足要求:单字节最高位都是 0,用来表示 ASCII 码,这样就完全兼容伟大的 ASCII 码;多字节的最高位都是 1,更具体的讲,N 字节模式,首字节以 “N个1再加0” 打头,后跟 “N-1” 个以 “10” 打头的字节。所以,先确定码点需要几个bit,然后确定需要几个字节,然后讲二进制码点依次放入除格式要求外的空位。解码也简单,扫到 N 个 “1” 就连同后面 (N-1) 个字节解码,然后丢掉格式 bit,进行解码。上面说到,Unicode 需要21(bit),所以 UTF-8 最多也只需要四个字节。
代码单元及 length 方法
原文地址:http://my.oschina.net/goldenshaw/blog/311848
- 什么是代码单元?UTF-8,UTF-16 和 UTF-32 中的 8,16 和 32 究竟指什么?
1. 一种转换格式(UTF)中最小的一个分隔,称为一个 代码单元(Code Unit),因此,一种转换格式只会包含整数个单元。
2. UTF-X 中的数字 X 就是各自代码单元的位数。
UTF-8 的 8 指的就是最小为 8 位一个单元,也即一字节为一个单元,UTF-8 可以包含一个单元,二个单元,三个单元及四个单元,对应即是一,二,三及四字节。
UTF-16 的 16 指的就是最小为 16 位一个单元,也即两字节为一个单元,UTF-16 可以包含一个单元和两个单元,对应即是两个字节和四个字节。我们操作 UTF-16 时就是以它的一个单元为基本单位的。
同理,UTF-32 以 32 位一个单元,它只包含这一种单元就够了,它的一单元自然也就是四字节了。
- Java 中的
string.length究竟指什么?
Returns the length of this string. The length is equal to the number of Unicode code units in the string.
返回字符串的长度,这一长度等于字符串中的 Unicode 代码单元的数目。
1. 我们知道 Java 语言里 String 在内存中以是 UTF-16 方式编码的,所以长度即是 UTF-16 的代码单元数目。不是我们想像中的所谓 “字符数”。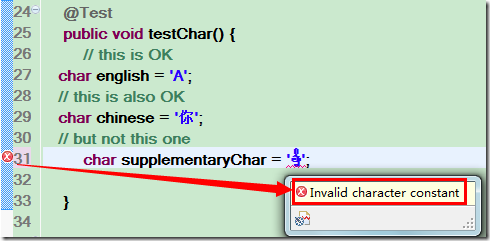
2. 在上图中,试图把这个字符赋值给一个 char 变量,发现编译器提示出错。为什么呢?因为Java 中 char 使用了 16 位,而这个字符在 16 位内已经无法表示,所以它放不进一个 char 中。可以看到,char 可以放一个英文字符,一个中文字符,那是因为这些字符都在 BMP 中,但却无法放置这个音乐符,eclipse 的即时编译立马就报错了: “Invalid character constant”(非法的字符常量)。
3. 增补字符的转义表示
Java 中的转义表示始终是以\u后接四个 16 进制数字为界的(其实就是 UTF-16 的代码单元),你不能简单像码点那样写成\u1D11E,这种写法相当于 “\u1D11”+”E”,即前面四位1D11做转义,后面当成正常的字母 E。如果要转义的字符码点超过U+FFFF,我们需要两个一对的转义\uD834\uDD1E来表示,从这里我们也可看到,所谓的转义表示其实就是 UTF-16 编码。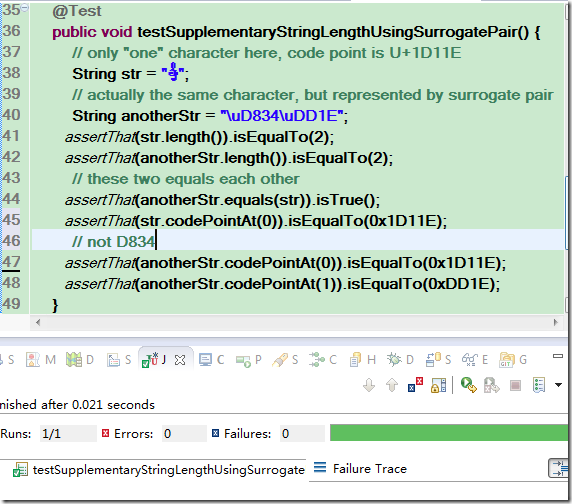
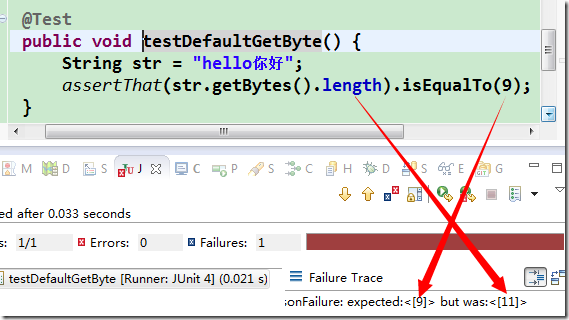
注意,本博主使用的是 [AssertJ] 这个自定义断言包,自行代码验证时没有该包时需要先行安装,或者转化为普通断言!!
这里证实了 string.length 的 API 所言不虚,图上的 str 只有一个字符,但它的长度却不是 1。它返回的的确就是 UTF-16 的代码单元的数目,而不是我们想像中的所谓 “字符数”。
另外,上图中还对两个 string 在 index=0 处的码点进行了求值(图中的 codePointAt() 方法),可以看到无论是以字符表示的 str(可以看到,char 表示不了,咱可以用 string)还是以代理对表示的 anotherStr,它们的码点都是0x1D11E,这也从另一个侧面证明了它们是同一个字符。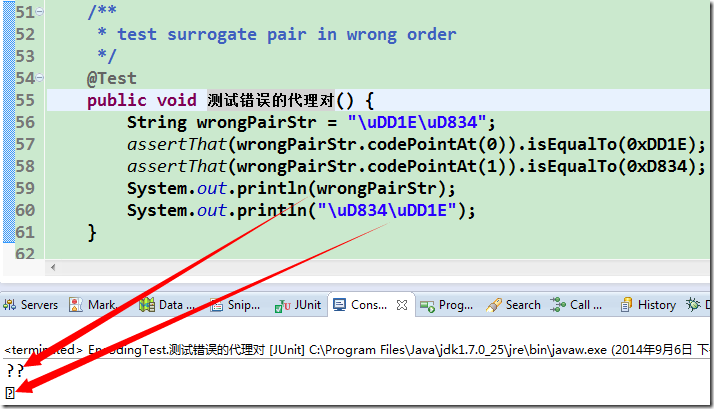
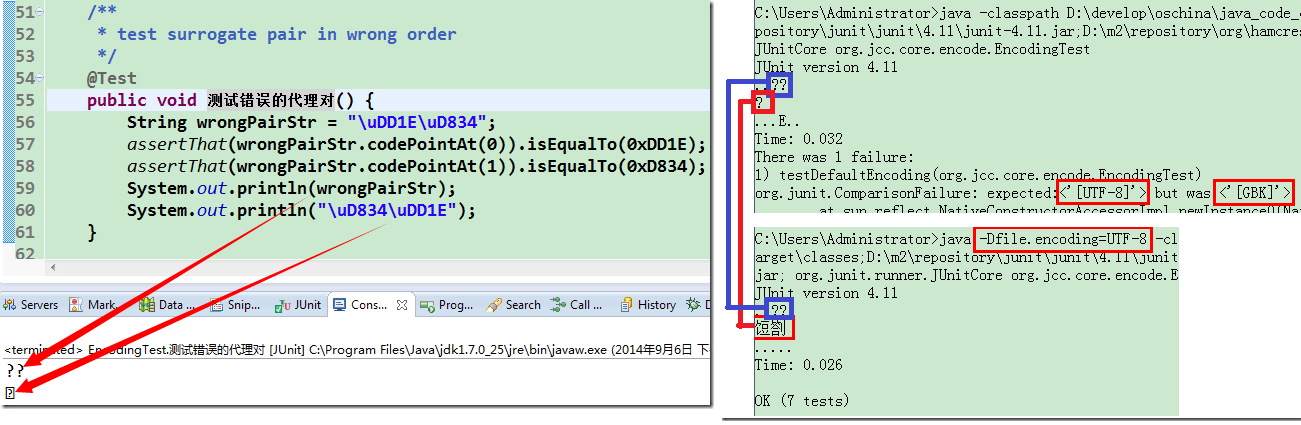
上述代码中把代理对写反了。前面篇章已经谈及,代理对必须严格按照先高后低的顺序来书写,这样\uD834\uDD1E其实是一个非法字符。
可以看到,输出了两个问号(其实就是两个非法字符,鬼知道是什么呀,显示个问号给你意思意思就是了),在 index=0 处的码点也变成了0xDD1E,而不是原来的0x1D11E了,而正常顺序则只输出一个字符。由于 console 字库原因,它不能正常显示,只是输出 “”。
这里也大概可以看出 codePointAt() 这个方法怎么使的。对于非法字符,也就是人家尝试解码但解码不了的,你输入什么码点就是什么;对于 SP 里面的,尝试以代理对解码,成功的话,码点就是该代理对转义字符对应的码点。所以,对于上面的音乐符\uDB34\uDD1E,codePointAt(0) 时发现这是个代理对,尝试跟后面一个字节解码,所以就得到音乐符的正确码点U+1D11E;codePointAt(1) 的时候就只剩下\uDD1E了,被当做非法字符解码,码点就是自己啦。
小结:
1. 这部分感觉对 Java 程序猿用处大些,不过,不同语言间是有共性的,这些共性的获取对我们正在学习的人来说,至关重要。
2. 上面提到 char 在 Java 中是两个字节,也就是在内存中的保存方式。什么汉字、什么字符,到底都是 “010101…”。怎么来的,字符有对应的码点,这个码点就跟字符集(比如这里的 Unicode )有关了;然后码点保存的时候需要编码,这个就看采用什么编码方式(比如这里 Java采用 UTF-16),编码后的字节数据基本上就是在内存中保存的数据了。至于格式、规则、语法就看具体的语言怎么定吧,char 在 C/C++中还只有一个字节呢,这些区别就需要额外注意了。其实根本的,我觉得还是理解赋值的字符真正在内存是怎么样的,char 不行,你就知道为什么不行了,也许就会换 char[] 试试,换 string 了。
3. 还提到的,或者说本部分主要说的,length() 用法。知道 Java 中,string 的 getlength 方法返回的是字符串中的 Unicode 代码单元的数目,即是,使用 UTF-16 编码的代码单元数目。至于更为具体的,在了解了代码单元是什么(这个就需要先看看上面的东东,还是那句话,概念性的东西先弄懂)之后,知道 UTF-16 两个字节为一个代码单元,加上一个汉字、字母等常见字符的 UTF-16 编码一般是两个字节,BMP 之外的特殊汉字就是四个字节了,可知 length 获取的长度跟字符串包含几个字符(不管是汉字还是其他字符)一般是相等的。此外,你还有明白具体到内存中该字符串是几个字节的?跟 C/C++ 中的 sizeof() 或者 strlen() 结果、内涵比较一下。
4. 了解到 转义字符 或者说 转义序列(Escape Sequence) 这种东西,这个上一篇文章(《借Qt中文乱码谈谈Coding中的编码问题》)有跟大家提到。我们比较熟悉的转义字符,无非 “\n”(换行符) 、 “\t”(制表符) 、 “\“(反斜杠) 、 “\’”(单引号) 、“\””(双引号),这些 C/C++ 也好,Java 也好都有、都差不多;上面 Java 中的这种 \uDB34\uDD1E 则是 Unicode 转义字符,感觉叫 UTF-16 转义字符 也行吧;还有一种就是 Qt的ui界面,使用的是一种 Octal Escape Sequence(八进制转义序列),其实就是 UTF-8 编码每个字节按照八进制显示。
为什么会有转义字符这种东西呢?因为,对于一段 转义文本(Escape Sequence) 不管是用 GBK 还是 UTF-8 编码的,ASCII 字符的编码是对应的,到哪看都不会变成 “&^&$(*()” 之类的乱码;或者说,为了避免源码字符集不同而导致最后程序的字符集不同,那些在不同字符集中有歧义的非 ASCII 字符转义成上面这种形式就可以避免了。总之,只要代码知道这段转义是按照什么编码转义的,那么不管到哪都能最后生成唯一的、与你原先输入一致的字符串。不过上面的代码,更像是我们某个字符打不出来,但我们知道这其中的原理,通过这种新的方式来构造这个字符。说到底,因为最终他们 在内存中保存的字节,或者说 “0101…” 序列是一样的,那么他们表示的意思肯定都是一样,至于这个意思要怎么看出来,就得按照合理的方式来看(解码),不然就看不到这个意思了,这就出现乱码了。 这些就是题外话了。
getBytes 方法及乱码初步
原文地址:http://my.oschina.net/goldenshaw/blog/313077
1.string.getBytes() 方法
1. 带参数的调用1
2
3
4
5
6
public void testGetBytesGbk() throws UnsupportedEncodingException {
String str = "hello你好";
assertThat(str.getBytes("GBK").length).isEqualTo(9);
//普通断言包好像写成:assertEquals(str.getBytes("GBK").length, 9);
}
因为 GBK 是变长编码,对 ASCII 字符采用一字节,汉字则是两字节,所以总的长度是 1×5+2×2=5+4=9,所以测试是通过的。
2. 无参数的调用:string.getBytes 它又可以不带参数去调用,这是最容易引发误解的,也是乱码的一大根源。
有人可能会想,既然 String 在内存中是以 UTF-16 编码,string.getBytes 是不是指它用 UTF-16 编码时所用的字节呢?答案是否定的。可能有人已经知道这个问题怎么回事,他们会说,没有参数时就使用系统的缺省编码。可是等等,这里所谓 “系统” 究竟指什么?操作系统?如果你就是这么认为的话,你可能又错了。
Eclipse 下的缺省编码测试结果:
在 Debug 视图中,选中运行的实例→右键→选择 “properties”,在弹出的窗口中,我们发现了猫腻(我亲测过,可惜是 GBK,不过你可以通过在 eclipse.ini 文件末尾添加一行
-Dfile.encoding=UTF-8 配置成与博主一致):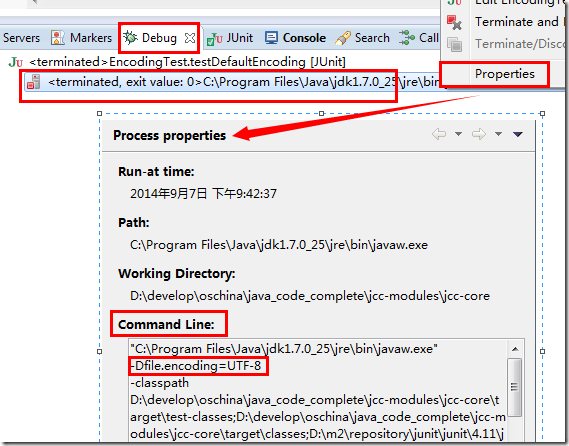
可以看到在 Command Line 中,eclipse 传入了一个额外的参数 “-Dfile.encoding=UTF-8”,我们可以大胆猜测一下正是这一参数改变了 string.getBytes 的缺省值!这样子,按照 UTF-8 编码 getByte(),1x5+3x2=11,和测试结果确实是一致的。通过下面的代码测试也确实验证了我们的假设。
1 |
|
2.命令行中的缺省编码:让我们跳过 eclipse,直接在命令行中验证一下。
下面是执行的结果,可以看到这下缺省确实是 GBK 了,所以测试失败了:
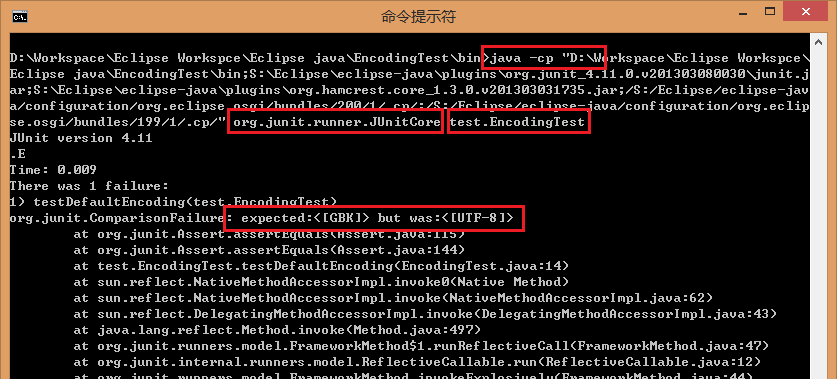
注意:原文作者的截图感觉有点混乱,这里重新验证了一下,然后对截图做出修改。验证的时候切记以 -cp 或者 -classpath 的形式修改 classpath 参数,而不要通过命令行的 set classpath=… 进行修改;其次注意测试类是否是带包的情况,带包则需要 包名.类名。
加上 -Dfile.encoding=UTF-8 再跑一下,果然,最后一行的 “OK” 表示测试通过了。
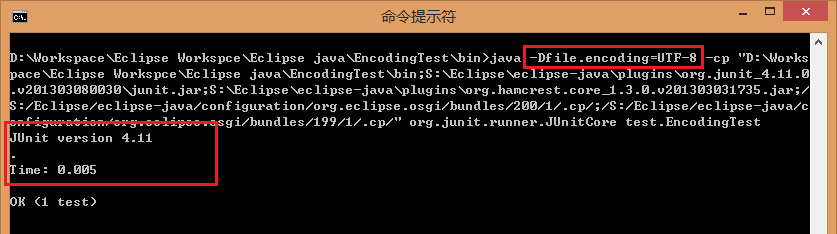
※ 那么现在一切已经很清楚了:
string.getBytes() 在没有指定参数的时候,它使用了 JVM 的缺省编码,如果启动 JVM 时没有明确设置编码,那么 JVM 就会使用所在操作系统的缺省编码(本人是在 Win8.1 简体中文系统下验证,GBK);但如果启动时明确地设置了编码,那么这一设置将成为 JVM 中的缺省编码!
至于其它的平台,具体是怎么样的,这个无法一概而论,读者可根据所在平台的具体情况作具体分析。
3.乱码的初步分析
右图中,命令行窗口错误地以 GBK 编码方式去解码一段 UTF-8 的字节流导致 的,让我们用测试来验证一下,并获取它的 GBK 编码看看:
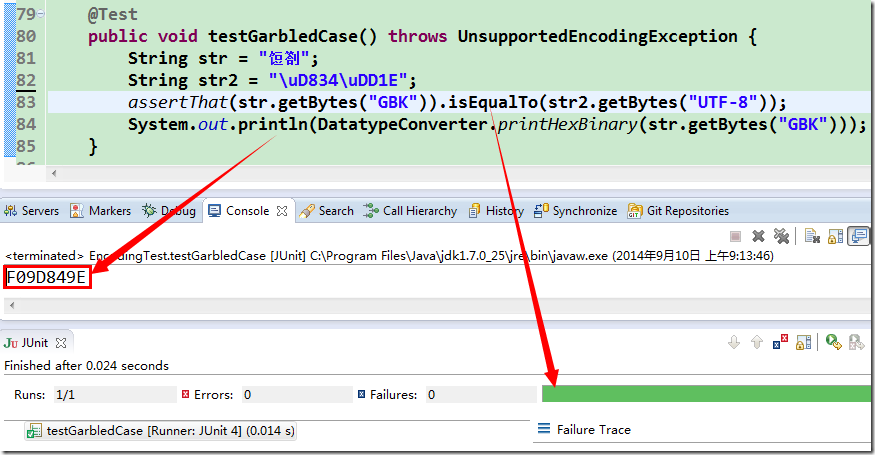
可以看到,测试是通过的,我们还打印了 GBK 的字节输出,发现是 F0 9D 84 9E,你是否觉得有点眼熟呢?再次看看前面发过的图:
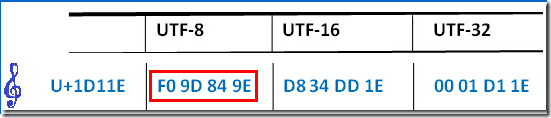
其实从测试通过我们就知道,这两个字节数组必然是相等的。那么现在我们也大概能明白这个乱码是怎么一回事了。
4.代码页(Code Page)
可以通过在命令行窗口中输入 “chcp” 来查看当前代码页,chcp=change code page(改变代码页)。要是不带参数就是输出当前的代码页;带参数则另起一个 console,并把此新开的 console 的代码页设置为指定的值。(右键命令行窗口→属性→选项,即可查看当前代码页)
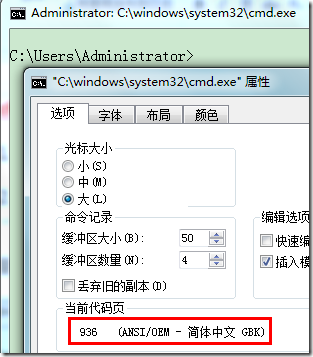
不那么严格地去看,代码页可以看作是字符集编码的同义词,比如 Code Page 936 就相当于 GBK,而 Code Page 65001 则相当于 UTF-8。
5.乱码的机制
1. 我们在代码中打印了一个代理对,即 U+1D11E 这个码点所代表的一个音乐符,在 JVM 的内存中就是以 UTF-16 的代理对编码形式存在的,可以想像在堆内存中有这么一个字节数组,它的值是 (D8 34 DD 1E)。
2. 我们在启动 JVM 时加入了 “-Dfile.encoding=UTF-8” 参数,所以缺省编码就成了 UTF-8。
3. 当打印发生时,会以缺省编码形式得到向外输出的字节流(字节数组),也即内部某处实质调用了 string.getBytes(“UTF-8”),这样就得到了一个临时的字节数组 (F0 9D 84 9E),其实就是 UTF-8 对 U+1D11E 的编码,JVM 向命令行窗口输出这样一个字节数组,自然是希望在命令行中打印出一个音乐符来。
4. 可是,命令行只是得到这么一串字节流 (F0 9D 84 9E),这里不包含任何的编码信息,所以它还是愣头愣脑 按着自己的缺省 GBK 来解码,它先拿到第一个字节 F0(11110000),一看最高位是 1,所以它认为这是一个汉字编码的第一个字节,于是它继续地读入第二个字节 9D,并把 (F0 9D) 合一起去查 GBK 的码表,这一查还真查到一个字,就是 “饾” 了(我们觉得这像是一个乱码,可计算机知道什么呢?),所以它很高兴地向外输出了这么一个字符。至于后面的(84 9E)呢,道理是一样的,所以又输出了另一个字符 “劄” 。
6.string.getBytes() 的本质
string.getBytes() 不过是把一种编码的字节数组转换成另一种编码的字节数组。
这里的一种编码在 Java 中就是 UTF-16,这个已经定了,你不用操心,你也改不了!
这里的另一种编码则由你来指定,不指定就用缺省,反正得要有,没有还转个球!
getBytes() 最好与 new String 一起结合来分析,一个是 String 到 bytes,一个是 bytes 到 String 。
7.让解码与编码一致,不就不会出现乱码了吗!
既然前面说到,由于命令行窗口采用了 GBK 来解码 UTF-8 的字节流,从而导致了乱码,自然,我们就想,如果把命令行窗口也设置成 UTF-8 编码,事情不就 OK 了吗?
1. 在 CMD 下验证:结果完全无法理喻(情况并不如我们想像那样,可以看到出来四个问号,按理应该只出来一个字符(哪怕不能显示)),可能是有 bug,看来在 windows 的命令行窗口下是无法验证这点了。
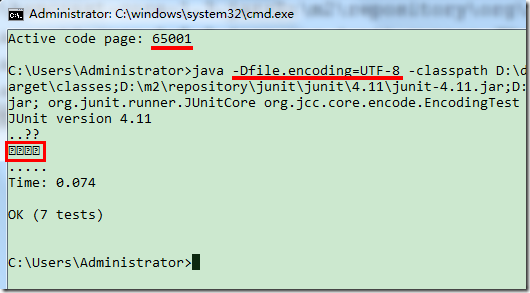
2. 在 git bash 上验证: 一样的问题,不清楚如何调整它的编码。
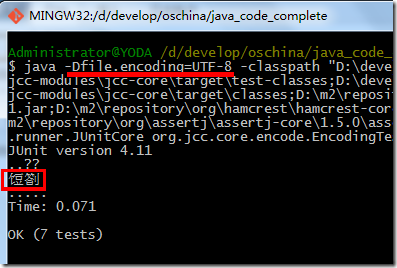
3. 在 cygwin 上验证:输出 $LANG 时可看到,它缺省已经是 UTF-8;这次终于算是正常了,可看到只有一个字符,不过由于字库不支持增补字符的原因而无法显示。
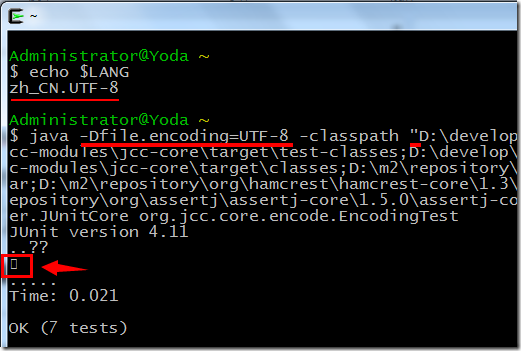
4. 非 Windows 平台,linux,mac…
这里原博主就没继续捣鼓了,不过,博主的捣鼓精神确实可敬,值得学习。上面也给我们展示了很多源于 linux,备受好评的东西,Windows 下的程序猿们舍不得离开,更不忍心只是傻看别人用,也在 Window 下弄一套。真是我们之福呀,大家有兴趣有机会多弄弄,定能学到好东西!!至于平台,个人觉得无所谓,扎实学好基本功才是关键,用熟就行
8.UTF-16 编码的问题
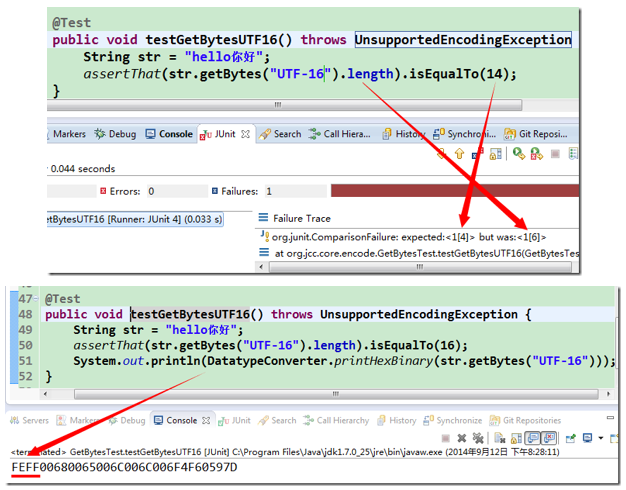
我们使用 UTF-16 再试下,可以先简单计算一下,“hello你好” 7 个字符都在 BMP 中都是两字节,所以7×2=14,对吧?尼玛!!又见红了!仔细看看,它说实际是 16,哪里又多出两个字节来?这里也没有什么增补平面的字符呀!没辙了,打印出来:就在最头部的地方,楞是多出了两字节 “FEFF“,这是啥呢?我想有人看到这里已经明白了,这就是 BOM。
小结:
1. 上节捣鼓 Java 的 getlength 之后,这节捣鼓了 string.getBytes() 。表面看是在学 Java 语法,实际上是一些很底层很基础的通用知识。了解了 Java 的单元测试 JUnit 以及一些运行参数,JVM 的编码信息等一些底层原理。
2. 大概知道上一篇文章里面说的乱码机制是什么了,无非是解码编码用的编码方式不一致造成。大多数情况是源用的是一种编码(比如上面打印输出的字节流通过 string.getBytes() 方式得到,用的是 UTF-8),使用数据的平台因获取不到源编码信息,又因显示需要,采用平台自己的解码信息(如上面不同的环境 CMD、git bash、cygwin )进行解码,所以造成了乱码。而解决办法嘛,无非就是让彼此一致,这个不简单。首先要弄清楚源用的是什么编码,尾用的是什么编码,为什么出现乱码了;其次,看怎样让彼此一致,改变源的编码还是改变尾的,哪种简单用哪种;最后,就是试一下,不行再改。如果清楚这一块的内容,我相信很快就能解决了。
3. 除此之外,编码方式还涉及到数据在内存中的存储,比如上面提到的,Java 就采用 UTF-16 的方式保存数据,这一个其实就跟上一节 getlength 关系很大了。可以想象,假如运行时的解码方式可以改变,使用了 UTF-16 之外的编码方式进行解码的话,这里又会出现另一种乱码啦。
4. 理解清楚 代码页(Code Page) 这个概念了,跟上一篇文章呼应;反正真和编码概念差不多,而且似乎只有微软才这么说。不管,就一概念,清楚了就清楚了,以后遇到了也不觉得慌。
5. BOM 终于出来了,跟 UTF-16 有大关系,感觉似乎就跟 UTF 有干系。
BOM
原文地址:http://my.oschina.net/goldenshaw/blog/323248
什么是 端法(endian)?
1. 大端法(Big endian)
以两个 UTF-16 的编码0x0048与0x4F60为例,如果我们把它们书写成00 48 4F 60,这样对我们而言也是非常自然的一种方式,00与4F都属于高位,我们又常常说 “高大高大” 的,高与大总是关系紧密,自然这样一种 高位在前的方式就是大端法(Big endian) 了。
2. 小端法(Little endian)
还是以两个 UTF-16 的编码 0x0048 与 0x4F60 为例,如果我们把它们书写成48 00 60 4F,那么这样一种 低位在前的方式就是小端法(Little endian) 了。
3. 大小端法应该是从存储层面考虑的
大端法放入内存,就单个编码而言,高位的字节反而放到了低地址上,而低位的字节却放到了高地址上。
4. 大小端仅仅是字节间的关系,这也暗示了只有多字节情况才会有所谓的端法,而通常又在偶数字节情况下更为普遍,如 UTF-16,UTF-32,这样才能更好分出 “两个端” 来。下面谈到 UTF-8 时将会再度阐述这一问题。每个单独字节里的 8 个位依然还是高位在前,无论大小端均是如此,下图是小端法单个字节内部以二进制表示的示意图:
端法与系统架构
1. 在 Windows 平台下,当使用记事本程序保存文件时,编码里有几个选项,可以看到一个 “Unicode” 和 “Unicode big endian”, 通过以上名称的对比及对大端法的特别标示,我们可以猜测出,Windows 下缺省是小端法(注:关于这里的 Unicode,实际就是 UTF-16 编码)。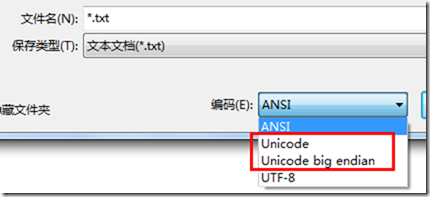
2. Windows 平台为何使用小端法呢?说起来与 CPU 制造商 英特尔(Intel) 又有很大关系。
内存(Memory)中使用端法其实又是受到寄存器(Register)中使用的端法的影响,因为两者之间经常要来回拷贝数据。英特尔的 CPU 就使用了小端法。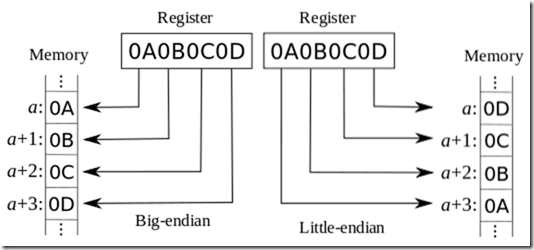
什么是 BOM?
1. 在记事本中以 ANSI 之外的三种编码分别保存一下 “hello你好”,分别命名为 UTF16BE.txt,UTF16.txt,UTF8.txt(分别对应 “Unicode big endian”,“Unicode”,“UTF-8”),使用 NotePad++ 以 16 进制方式查看,注:不熟悉 NotePad++ 的读者可以参考这里《NotePad++》。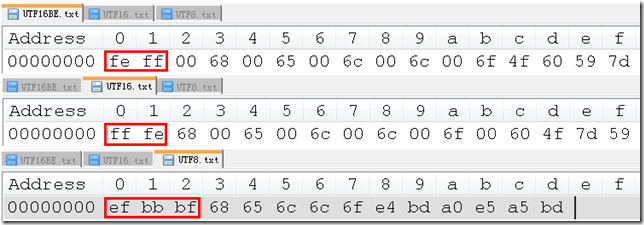
2. BOM=Byte Order Mark,翻译过来就是 “字节顺序标识”,也即是上图中红色框中的部分。
自然地,这里所谓的字节顺序其实就是指使用了哪种端法。
前面说到,getBytes(“UTF-16”) 得到的缺省 BOM 是 “FEFF”,可见 JVM 中缺省是大端法,这与 Windows 平台下缺省为小端法恰好相反。
3. 下图是 UTF 各种 BOM 的一个汇总,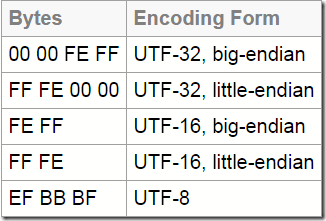
BOM 其实就是U+FEFF这一码点,“EF BB BF” 就是这一码点在 UTF-8 下的编码;U+FEFF称为 “zero-width non-breaking space”,字面义: 零宽度非换行空格。也即碰到时把它解释成这样,显示上的实际效果就是啥也没显示。在用作 BOM 之后,Unicode 不再建议这样去解释(deprecated),而是建议用U+2060来代替,U+FEFF就作为 BOM 的专用。U+2060称为 “Word Joiner”(字面义:词连接器),缩写为 “WJ”。
UTF-16 BE(Big Endian)的 BOM 是:FE FF(大端,高位在前,又因为U+FEFF在 BMP 之内,所以 BOM 就是FE FF);UTF-16 LE(Little Endian)的 BOM 是:FF FE(类似,不过因为是小端,低位要在前,所以 BOM 就是FF FE);
UTF-8的 BOM 是:EF BB BF(这个是U+FEFF的 UTF-8 编码);
UTF-32 BE(Big Endian)的 BOM 是:00 00 FE FF(大端,高位在前,UTF-32 只需要对码点U+FEFF补足零就行,所以 BOM 就是00 00 FE FF);UTF-32 LE(Little Endian)的 BOM 是:FF FE 00 00(类似,不过因为是小端,低位要在前,所以 BOM 就是FF FE 00 00)UTF-8 的 BOM
java 中,UTF-8 缺省不带 BOM,这点与记事本又不同:
按 Unicode 组织的说法,UTF-8 可带可不带BOM,不作强制要求,但 不推荐用 BOM,原因之一是为与 ASCII 的兼容。另: UTF-8 也不存在所谓的大小端 两种情况,统一为大端法,BOM 仅仅作为一种所用编码的指示。
在 eclipse 中,以 UTF-8 保存时就没有 BOM,但它的编辑器也能正确处理带 BOM 的情况。
插一段与本节相关的评论区信息
网友 1 提问博主:楼主有时间能否分析一下 操作系统和输入法是怎么处理编码 的
网友 2 补问:关键是操作系统的显示,即所谓的 机内码
博主回答:这个问题有点大,我可不是专家,只是有一点心得而已。JVM 在内存中字符串都是 UTF-16,.net 平台也是如此,新的 windows 平台内核都是 UTF-16,早期情况就复杂了,至于 linux 平台,据说是 UTF-8,没有详细了解,不敢妄下结论。至于输入法程序在它的进程空间如何表示字符串,如果它 能支持 unicode,那么在 windows 平台下应该用的就是 UTF-16 了;如果不支持 unicode,那么采用 GBK 之类 的来表示也是有可能的。对输入法我了解也不多,这些也仅是个人猜测。如果读者中有更清楚的,欢迎他们留言讨论!
小结:
1. 老子终于明白带不带 BOM 之什么是 BOM 了!本质就一字符,一个无法显示的字符,其他不知道有木有,反正被 UTF 用来区分大小端了。什么是大小端,自己看概念去,一看就懂。BOM 的码点是 U+FEFF,然后用在不同的 UTF 编码,就按照相应编码下是什么,以及符合大小端定义。
2. UTF-8 可是能用 1-4 字节表示,奇数的话说大小端没什么意义,所以特殊一点,统一为大端,而只区分带不带 BOM(EF BB BF)。为了与 ASCII 兼容,建议不带 BOM,但是带不带,反正我们理解了这些东西,就能够处理了。就像上一篇文章里面因为没带 BOM 带来的编译警告,让我们知道 VS2013 的 cl 编译器 不能识别不带 BOM 的 UTF-8,想想也无伤大雅,就老老实实带上咯。
3. 到这里应该对 UTF 的编码有了比较全面的了解了。从 Unicode 字符集,到 Unicode 码点,再到由码点衍生出来的各种编码 UTF-8、UTF-16、UTF-32,再引入端法,进一步区分出带不带 BOM 的 UTF-8、UTF-16 BE、UTF-16 LE、UTF-32 BE、UTF-32 LE。
ASCII 和 ISO-8859-1
原文地址:http://my.oschina.net/goldenshaw/blog/351949
ASCII
它的全称是 American Standard Code for Information Interchange(美国信息交换标准代码),是一个 7 位字符编码方案。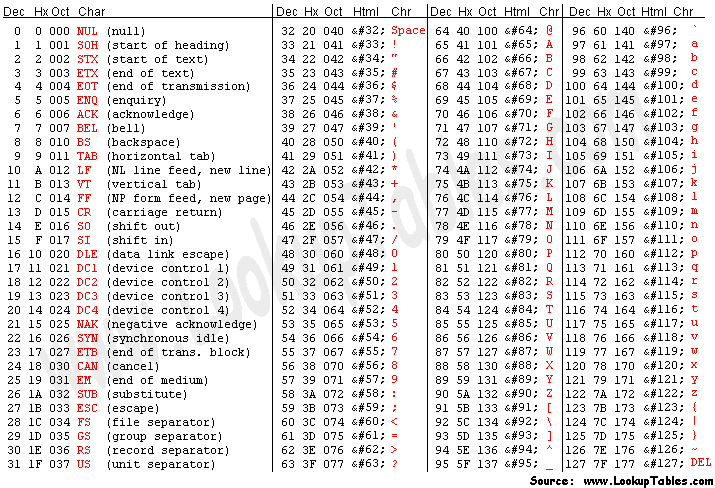
1. 控制字符:32 以下的及最后一个 127 是所谓的控制字符。(0x00~0x1F以及0x7F),即上图最左边一列的 32 个字符及最右边一列最后的一个字符(DEL,删除)。
熟悉的有 0x09(TAB,horizontal tab,水平制表符),0x0A(LF,line feed,’\n’换行符),0x0D(CR,carriage return,’\r’回车符),其它的很多现在已经是废弃不用了。
关于 回车换行(‘\r\n’),在屏幕还不普及的时代,结果输出经常是依赖于所谓的电传打印机,打印头沿着打印杆从左向右移动并打印出一个个字符,当碰到一个 回车符(CR,0x0D,’\r’)时,打印机就指示打印头重新回到最左边的位置上,这即是传统意义上的回车了。(你可以把打印头想像成一辆小车,回车即是退回原处,现代意义上的回车则通常包含回车与换行两个动作)
回车符后常跟着一个 换行符(LF,0x0A,’\n’),打印机收到换行符就会指示滚筒滚动,这样,打印头就对准了纸张上的新的一行。如果没有换行,新的打印输出就会重叠在上一行上,有时走纸不顺畅时也会造成这种后果。
目前,在 Windows 系统上,回车键会产生两个字符 CRLF,一起表示换行;Unix/Linux 之类的则单独用 LF 表示换行;而苹果的 Mac 则单独用 CR 来表示换行。
2. 由于只定义了 27=128 个字符,用 7bit 即可完全编码,而一字节 8bit 的容量是 256,所以一字节 ASCII 的编码最高位总是 0,这为后来的编码方案兼容它带来的便利。ISO-8859-1
ISO-8859-1 又称 Latin-1,是一个 8 位单字节字符集,它 把 ASCII 的最高位也利用起来,并兼容了 ASCII ,新增的理论空间是 128,但它并没有完全用完:
可以看到,新增部分也保留了前面的 32 个位置(中间绿色部分,0x80-0x9F),与前面的 ASCII 部分类似,所以实际只增加了 128-32=96 个,主要是 西欧的一些字符,另外可以看到 乘号(0xD7) 和 除号(0xF7) 也被包含进来了。
ISO-8859-1 能与 ASCII 兼容,同时它的适用范围又较广,一些协议或软件把它作为一种缺省编码,当然,现在更好的选择是 UTF-8。
小结:
1. Unicode 相关的编码讲完了,剩下这些部分就像边角料一样,比较零散,但运用类似的思路就能够很快理解了。
2. 这一节基本都是理论的知识,到这里才和大家介绍 ASCII 编码,一个不复杂但很重要的编码,就像之前说的,是很多编码的大大,能不能很好的兼容 ASCII,往往是一种编码是否受欢迎的硬性指标。
3. 还介绍另一种编码,我们在捣鼓 VS2013 的时候可能会注意到,Latin-1 编码。大概就是在 ASCII 基础上扩展出来的一种编码吧,我们要知道的是,人家利用其 ASCII 的最高位,扩展了一些西欧字符,而且是兼容 ASCII 的就行了。
GB2312、GBK、GB18030
原文地址:http://my.oschina.net/goldenshaw/blog/352859
GB 系列包括 GB2312,GBK,GB18030。前面已经提过,GB=Guo Biao=国标=国家标准,至于所谓的 2312 就是一编号了,没有其它特别的意义,18030 类似。GBK 没有编号,所以它实际上并不是国家标准,只是一个事实标准,GBK 中 K 指“扩展”的意思。
GB2312:采用了所谓的二维区位编号,是一个 94×94 的表格,理论上有 94×94=8836 个空间;横的叫区,竖的叫位,总共 94 个区,区和位的编号都从 1 开始。粗略有三大部分。
1. 中间黑色的主体部分即是汉字区了,具体为 16-87区,共 87-16+1=72 个区,理论空间为 72×94=6768。
第 16-55 区:一级汉字,3755 个(以拼音字母排序)
第 56-87 区:二级汉字,3008 个(以部首笔画排序)
2. 最下面的 88-94 区 是有待进一步标准化的空白区。
3. 关于前面的 01-15 区,
01-09 区 为符号、字母、日文假名等,部分区还有空白位。
03 区 即是对应 ASCII 字符的全角字符区。输入法的全角模式下输入的即是这些字符。
10-15 区 也是有待进一步标准化的空白区。
4. 各区的一个具体情况:1
2
3
4
5
6
7
8
9
10
11
12
13第01区:中文标点、数学符号以及一些特殊字符
第02区:序号
第03区:全角西文字符
第04区:日文平假名
第05区:日文片假名
第06区:希腊字母表
第07区:俄文字母表
第08区:中文拼音字母表
第09区:制表符号
第10-15区:未定义
第16-55区:一级汉字(以拼音字母排序)
第56-87区:二级汉字(以部首笔画排序)
第88-94区:未定义区位码
在上图中还标出了一个汉字 “啊”,它就是 GB2312 方案中的天字第一号汉字,它处于 16 区 01 位上,所以它的区位码即是1601。
所谓区位码就是这一 94×94 的大表格中的行号与列号了,均从 1 开始编号。国标码
将区位码的区和位分别加上 32(=0x20) 就得到了国标码。
“啊”的区位码是 16-01,分别加 32,得到 16+32-01+32=48-33,即是国标码。当然,你通常应该写成 16 进制,48-33 即是 0x30-0x21,所以 3021 即是 “啊” 十六进制的国标码,使用两字节保存,30 为高字节,21 为低字节。GB2312 方案规定,对上述 94x94 表格中任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示。
1. 为何不直接采用区位码呢?为什么要加 32 呢?你也许还记得前面说到 ASCII 时,前面 32 个字符是控制码,中文系统自然也不能少了这些控制码,为了不与这些控制码冲突,加上 32 就能跳过它们了。
2. 一字节有 128 个空间,128-32=96,实际上,ASCII 中第 127 个也是控制码(DEL, 删除),再减去就还有 95 个有效位,再加上区位从 1 开始,又损失了一位,所以最终只有 94 个有效位了,这也是前面为何是一个 94×94 的表格。
3. 国标码的定位实际应该是与 ASCII 一致的,是作为国家信息交换的标准码。从设计上看,它并没打算兼容 ASCII。机内码
将国标码高低字节分别加上 0x80(=128)就得到了机内码(有时又叫交换码)。128 的二进制形式为 10000000,加 128,简单地讲,就是把国标码最高位置成 1.至于为什么要这样呢?我想你应该也清楚了,就是要 兼容 ASCII,ASCII 最高位为 0,国标码加 128 后,高低字节的最高位都成了 1,这样就与 ASCII 区分开来。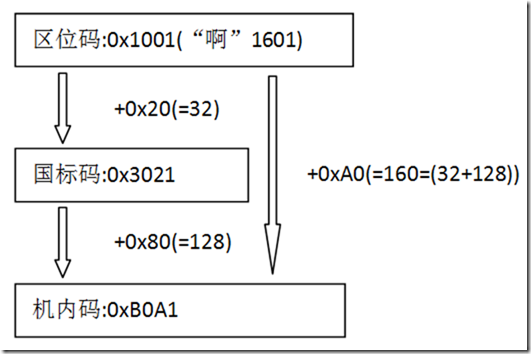
1. 如果你新建一个文本文件,录入 “啊” 字,以 GB2312编码 方式保存(使用 GBK 即可,它兼容 GB2312),再用十六进制查看,你会发现使用的是机内码:
2. 虽然我们常把 GB2312 称为国标码,但我们应该清楚,实际存储使用的是机内码,通常说到 GB2312 编码 时指的就是这个机内码了。它能 兼容 ASCII,是一种变长的编码方案,对 ASCII 中的字符(也即所谓的 “半角西文字符”)采用一字节编码,最高位为 0;对区位表中的字符采用两字节编码,且每字节最高位均为 1,以此区分。
3. 三种码在 256×256 坐标中的位置的一个示意图,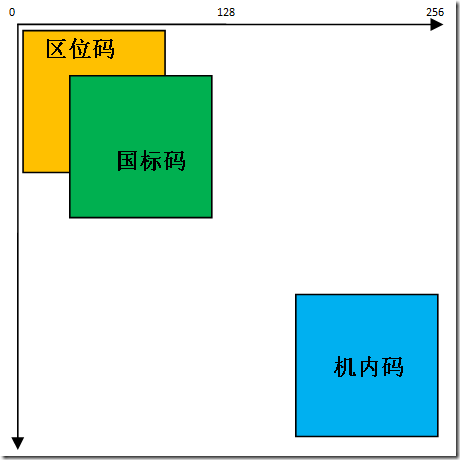
区位码 (x1,y1),x1、y1∈(01~94);
国际码 (x2,y2),x2=x1+32、y2=y1+32;
机内码 (x3,y3),x3=x2+128、y3=y2+128.GBK: GBK 是对 GB2312 的一个扩展,兼容 GB2312,因此也兼容 ASCII,也是一个变长编码方案。下面是一个简介:
GBK 总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。
1. 首字节从 0x81 开始,这意味着最高位肯定是 1,这就兼容 ASCII;第二字节从 0x40 开始,不是从 0x00 也不是从 0x80 开始。因为不是从 0x80 开始,这意味着第二字节最高位也可能是 0,这点与 GB2312 不同,GB2312 确保了无论是高低字节最高位均是 1。
2. GBK 还是 UTF-8?
※ GBK 使用两字节保存中文,也能兼容 ASCII,而对常用汉字,UTF-8 都是采用三字节编码,因此 无论是全中文还是中英文混合的情况,GBK 保存的效率都要好于 UTF-8。
※ 但它也有些不好的地方,比如它不能支持一些国际性的文字,在国际化,通用性方面它肯定不如 UTF-8;就汉字而言,由于容量空间的限制,它也无法收录更多的汉字了。GB18030: GB18030 前后发布了两个标准,最新的是 2005 年发布的 GB18030-2005(《信息技术 中文编码字符集》),2000 年还有一版 GB18030-2000。
1. 下面是一些简介(针对最新的 GB18030-2005):
它也是一个多字节编码方案,有一,二,四字节三种变长组合。
它的编码空间很大,高达 160 万(约数),这甚至超过了 Unicode 规定的 110 万(约数)。
它兼容 GB2312,基本兼容 GBK(只有很少几处不同)。
它收录高达 7 万多的汉字,Unicode 中的 CJK 统一汉字,CJK 统一汉字扩充 A,CJK 统一汉字扩充 B 均收录了进来。
它还支持许多少数民族如藏、蒙古、彝、维吾尔等的文字。
2. GB18030 作为一个强制标准,但由于采用了高达四字节的情形,无论是操作系统还是各种应用软件,可能涉及许多调整才能很好地支持,这决不是一件简单的事情。
作为国际性标准的 Unicode,BMP 以外的字符的处理与显示都还有很多不完善,所以如果 GB18030 没有得到很好的支持,那也不足为奇了。
小结:
1. 这一节主要介绍与我们中国人,或者说汉字息息相关的 GB 系列编码,包括 GB2312、GBK、GB18030,具体的国标不国标,这个并不重要;我们只需了解日常编程中经常用到的两种编码保存方式 GB2312 和 GBK 就行了,剩下那些,没什么卵用,看看知道就好。
2. 要清楚他们都兼容 ASCII,而且是怎么兼容的?GB2312 定义了一套所谓的 区位码,但实际编码是通过叫做 机内码 的形式,这种码需要两个字节,而且每个字节最高位都是 “1”;我们知道 ASCII 编码使用一个字节,而且最高位为 “0”。这样,就能够通过字节最高位判断是按照 ASCII 解码还是按照 GB2312 解码了,最高位为 “1”,连同下一个相邻字节一起按照 GB2312 解码;最高位为 “0”,该字节需要按照 ASCII 解码。
3. GBK 兼容 GB2312,也兼容 ASCII。唯一的区别是,GB2312 的第二字节最高位肯定为 “1”,而 GBK 扩展了不为 “1” 的可能,但只要某个字节最高位为 “1”,那么他就必须和下一个相邻字节一起按照 GBK 解码,这样也能区分开 ASCII 解码的字节。不过可以想象,假如某些字节丢失了,对于 GB2312 所有丢失字节的汉字数据均会发现错码;GBK 则可能将部分汉字数据按照 ASCII 解码了,可能就会错上加错了。
4. 此外,还需要了解什么是 区位码?国际码?机内码?三者之间如何相互转换,最主要是如何从 GB2312 定义的一套 区位码 转换到实际编码保存的机内码。
Summary
上面就是所有的该系列博文的重要笔记,现在回过头来看,思路变得非常清晰了。
从字符集和编码的区别出发,紧接着介绍字符集需要定义的码点,然后对码点采取不同方式进行编码,主要方案便是定长方案或者变长方案。这些就是比较基础的一套理论知识;
接下来,具体应用这套理论知识,从常见的 Unicode 开始,通过实际例子进一步阐述。详细介绍 Unicode 字符集,也就是 Unicode 码点集合,主要涉及 BMP、SP 等概念,来源于 Unicode 一种划分、归档方式。然后就是具体的编码方案了: UTF-32、UTF-16 和 UTF-8,包括他们的具体实现方式,如 UTF-32 是定长 4 个字节,UTF-8 是变长 1-4 个字节;如何从码点转化到具体的编码数据,这个主要围绕如何扩充容量同时灵活存储,如: UTF-16 通过代理区、代理对编码 BMP 外的字符,如何转化?UTF-8 使用变长数据格式要求安放码点,同时兼容 ASCII;最后,就是通过 BOM 进一步介绍 UTF 编码,包括大小端和 UTF-8 带不带 BOM。
解决了庞大的 Unicode 系列编码,还需要了解其他一些常见的编码方式,包括 ASCII 还有与汉字息息相关的 GB2312 和 GBK 编码,在 UTF 编码的基础上就不难理解了,之中关键点是如何实现与 ASCII 兼容。
其中,围绕 UTF 系列编码,通过 Java 底层原理介绍,讲述字符如何在内存中保存啊,如何流动,以及为何出现乱码的根本原因,充分了解 “0101…” 和具体字符之间双向过程中的细节,乱码现象不再可怕。