本文基于对有关资料的理解,同时通过代码测试验证,为大家讲述OpenCL入门时几个比较重要但又令人困惑的小知识点,包括:
1. NDRange如何设置(work-item&work-group)?
2. 如何获取kernel执行时间?
3. 如何获取kernel编译信息?
(一)NDRange如何设置?

- 结合上图我们分析一下下面设置NDRange(Global Dimemsion Index Ranges)部分的代码。
1 | /* Set number of work-items in a work-group */ |
- 首先,我们参考《The OpenCL Specification》,函数
clEnqueueNDRangeKernel的官方规范如下: -
1
2
3
4
5
6
7
8
9cl_int clEnqueueNDRangeKernel ( cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)- 其中,需要注意的是,
work_dim指定 NDRange 的维数,目前暂支持1-3分别表示X、Y、Z三个维度;global_work_offset当前必须为 NULL,暂时不理他;num_events_in_wait_list指明函数 clEnqueueNDRangeKernel 执行之前需要等待完成的事件数目,event_wait_list则是与之对应的事件列表(这里暂时不理他,后续课程会进一步介绍事件对象cl_event);最后一个参数event则是函数执行完成会触发的事件,后面获取 kernel 执行时间部分将会用到,这里也可以暂不考虑;重点在于global_work_size和local_work_size两个 size_t 数组,数组大小与设置的维度work_dim保持一致。其中 global_work_size[0]、[1]、[2] 分别对应X、Y、Z三个维度(local_work_size相似)。在每一个维度上,local_work_size用于设置一个 work-group 中 work-item 的数目,global_work_size则是对应维度上总共的 work-item 数目,所以,对应维度上 work-group 的数目自然就是 $\frac{(global\_work\_size + local\_work\_size-1)}{local\_work\_size}$。 - 此外,OpenCL 要求各个维度中 work-group 数目能够整除 NDRange 索引空间各个维度的大小
global_work_size,这样可以保证所有工作组都是满的而且大小相同,均为local_work_size。 - 结合代码,这里设置的 NDRange 只有X维度,localWorksize[1] = {8}表明该维度上每个 work-group 有8个 work-items,而该维度上总共的 work-items 为16个,所以计算出来的 numWorkGroups 为2,表示X维度上总共有2个 work-groups。为了保证满足整除的要求,我们最后通过 globalWorkSize[1] = { numWorkGroups * localWorkSize } 设置X维度的大小。
- 因此,在上图中,get_work_dim() 返回 NDRange 索引空间的维度自然为1(只有X维度);get_global_size(0),下标0表示返回X维度上的大小(下标若为1、2则表示Y、Z维度),为16;get_num_groups(0) 返回X维度上 work-group 的数目,为2;而对于X(其他维度类似)维度上的每个 work-group,通过get_group_id(0),(下标0指X维度)可以获取当前group的ID,而通过 get_local_size(0) 可以获取当前 group 里的 work-items 数目。所以,对于总大小为16的一维内存对象,分成的两个local_work_size为8的work-group分别是下标0-7和下标8-15,前者group-id为0,后者为1。此外,对于维度上的一个work-item,通过get_global_id(0)可以获取其在该维度(下标0表示X维度,1、2为Y、Z)上的ID,get_local_id(0)则得到其在group中的ID。所以,对于上图中用黄色标记的work-item,为整个一维内存对象的第12个元素,为第二个work-group中的第4个元素,故其全局id和组内id分别为11和3(这里与普遍的C规范一致,下标从0开始计数)。
- 其中,需要注意的是,
- 下面我们举一个NDRange为二维的例子(参考 《OpenCL Programming Guide》 P8-P10)。
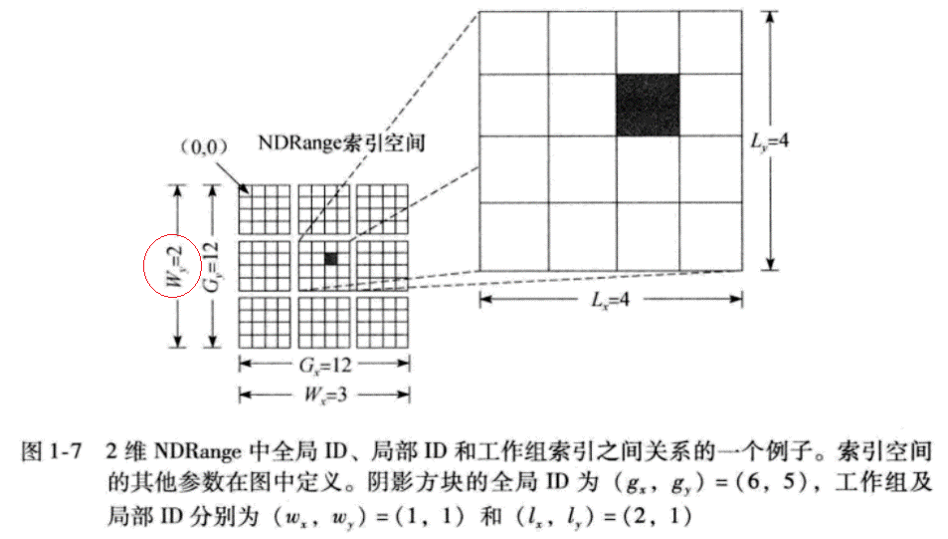
Figure from 《OpenCL Programming Guide》 - 该图表示一个二维的NDRange,其中每个维度的大小均为12。每个小方格表示一个work-item,12个小方格组成的中方格表示一个group,最外层由9个中方格组成的大方格则是整个NDRange空间。Gx=12 Gy=12指明全局空间大小,每个维度均为12; Wx=3 Wy=3指明组索引空间,每个维度都是3个组(上图红圈标识的地方有错,觉得应该是3); Lx=4 Ly=4则指明组内空间大小,每个group每个维度上大小均为4(这也是Wy应为3的原因,整个Y上有12个work-item,每个组Y上大小为4,所以Y维度上应该有3个group)。下面是实现上述NDRange空间的代码:
-
1
2
3
4
5
6int Lx=4, Ly=4;
int Wx=3, Wy=3;
size_t localWorkSize[2] = {Lx, Ly};
size_t globalWorkSize[2] = {Wx*Lx, Wy*Ly};
cl_event ev;
clEnqueueNDRangeKernel(cmd_queue, kernel, 2, NULL, globalWorkSize, localWorkSize, 0, NULL, &ev);
代码实现与上述一维空间基本一致,不同的主要是,这里 clEnqueueNDRangeKernel() 第三个参数是2,表示2维空间,而且 localWorkSize 和globalWorkSize 的大小都变成2,与该参数保持一致。1
2
3
4
5
6
7
8
9
10
11
12
13
14// Get global position in X direction
int gx = get_global_id(0);
// Get global position in Y direction
int gy = get_global_id(1);
// Get group position in X direction
int wx = get_group_id(0);
// Get group position in Y direction
int wy = get_group_id(1);
// Get local position in X direction
int gx = get_local_id(0);
// Get local position in Y direction
int gy = get_local_id(1);
对于上图中的黑色小方格表示的work-item,get_global_id得到他X、Y上的全局ID应为(6,5),从左往右数第7个,从上往下数第6个嘛。get_group_id得到他所在组的group-id也应该为(1,1),从左往右数第2个,从上往下数第2个。至于其在所在组的组内ID则是(2,1),从左往右数第3个,从上往下数第2个。
通过上面的讲解,现在你应该对所谓的NDRange有比较清楚的认识了。如果还存有疑惑,建议您参考一下《OpenCL Programming Guide》第8到10页内容。
这里,还需要指出的是,上面的二维空间的例子,两个维度上的local_work_size是一样的,那么是不是一定要保持一致呢?为了验证这个想法,我试着修改一下之前做过的一个矩阵乘法的例子关键代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14const int P = 3;
const int M = 5;
const int N = 6;
//....
/* Execute OpenCL Kernel */
size_t globalWorkSize[2] = {N, P}; // size_t globalWorkSize[2] = {N, P};
size_t localWorkSize[2] = {N, P}; // size_t localWorkSize[2] = {3, 3};
cl_event ev;
err = clEnqueueNDRangeKernel(command_queue, kernel, 2, NULL, globalWorkSize, localWorkSize, 0, NULL, &ev);
//....
1 | __kernel void vmultiply(__global float* result, __global const float* m_a, __global const float* m_b, |
这里是一个3x5的矩阵和一个5x6的矩阵的乘法,我们知道其结果为一个3x6的矩阵,所以我的思路是构建一个二维NDRange空间,X、Y维度上的总大小分别为6和3,这里可以想象成一个3行6列的矩阵。因为结果矩阵中每个元素的计算都是独立的,因此可以对每个元素的计算进行并发,kernel函数就是按照这种思路写的。
我们关注NDRange是如何设置的。两个维度上的glbal_work_size显然为6和3;一开始将每个维度上的local_work_size也设置为6和3。联想我们上面介绍的,这样的话,每个维度上都只有一个group,那么计算矩阵乘法的所有work-item就在同一个group了。这里也验证了,不同维度上的local_work_size是可以不同这一说法。
又将每个维度上的local_work_size均设置为3,这样的话,Y维度上只有一个group,X维度上就有6/3=2个group,这样计算矩阵乘法的所有work-item被分在两个group了,get_global_id(0)在0-2的为一个group,在3-5的为另一个group。这里也可以推测出,对于不同维度上group的数目是可以不同的。
此外,上面的例子对于矩阵(二维数组)传递到内核函数是以内存对象引用的形式实现的,那么对于当前的work-item对应的X维度上的rol,Y维度上的row,我们需要将其映射到该内存对象引用上,映射的形式实际上和二维数组映射到一维数组相似,[row*Width+col]<==>[row][col]。
最后,还有一个地方需要注意的,我们通过numGroup = (N + localWorkSize - 1) / localWorkSize这种方式来计算已经设定了localWorkSize的维度上,满足N个work-item需要的work-group数目numGroup,再将numGroup*localWorkSize得到的global_work_size作为NDRange设置的参数以满足上述整除的要求。假如N能够整除localWorkSize还好,这种情况下N和global_work_size一样,而且每个group里面不会有多余的work-item。但是,假如N不能够整除localWorkSize,尾端就会存在一个group,这个group末尾的某些work-item只是我们为了满足整除的要求而添加进去,是多余的,应该排除掉的。这就是上述main.cl中if((row>=0) && (row
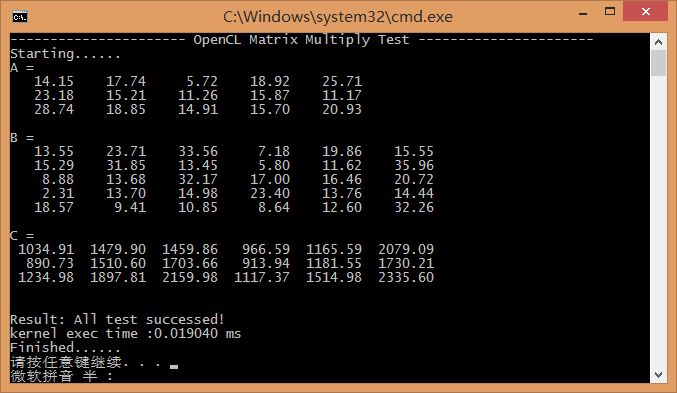
上述例子参考代码如下,VS2013 工程可以点击获取 访问密码 sefv。最终的测试结果如下:
1 | // vmultiply.cpp : 定义控制台应用程序的入口点。 |
1 |
|
(二)如何获取kernel执行时间?
解决了最麻烦的 NDRange,我们终于可以轻松地干点其他了。一个比较棘手的问题就是,我们有时想分析一下内核函数的执行效率,获取其执行时间不失为一个好方法。如上图所示,在程序执行结束前,不凡将内核执行时间打印,通过对内核执行时间进行比较,我们可以对内核效率做出分析。例如在不同 NDRange 设置下比较内核函数执行时间等。那么怎么获取到内核函数执行时间呢?OpenCL 提供了一套有效的API。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/* Create Command Queue */
cl_command_queue command_queue = clCreateCommandQueue(context, device_id, CL_QUEUE_PROFILING_ENABLE, &err);
//...
cl_event ev;
err = clEnqueueNDRangeKernel(command_queue, kernel, 2, NULL, globalWorkSize, localWorkSize, 0, NULL, &ev);
err = clFlush(command_queue);
err = clFinish(command_queue);
//...
// 计算kerenl执行时间
cl_ulong startTime = 0, endTime = 0;
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_START,
sizeof(cl_ulong), &startTime, NULL);
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &endTime, NULL);
cl_ulong kernelExecTimeNs = endTime - startTime;
printf("kernel exec time :%8.6f ms\n", kernelExecTimeNs*1e-6);
首先,上面已经说过,执行完 clEnqueueNDRangeKernel() 会触发一个事件,我们通过 ev 获取。之后通过 clGetEventProfilingInfo() 便能得到内核函数开始执行的时刻 startTime 以及执行结束的时刻 endTime,这样便能够得到整个内核函数执行的时间(单位:ns)。需要注意的是,为了能够获取事件信息,需要在 clCreateCommandQueue 创建命令队列的时候通过 CL_QUEUE_PROFILING_ENABLE 参数设置队列为可配置的,这样才能够保证通过 clGetEventProfilingInfo() 能够获取到执行信息。
此外,如果按照上述步骤做了,还是不能够正确获取到执行时间,建议检查一下 clEnqueueNDRangeKernel() 这一部分,之前因为将 localWorkSize 设置为 NULL 导致获取的执行时间出错。使用 clEnqueueTask 似乎也不行,希望你用到的时候注意一下,如果出现问题,可以按照上述给出的参考代码进行修改。
(三)如何获取kernel编译信息?
另一个个人觉得比较实用的就是,kernel 函数是通过程序在运行的时候进行编译的,那么,如果能够在编译出错的情况下获取到错误信息,对我们修改 kernel 函数会有很大的帮助。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// ...
/* Load the source code containing the kernel*/
FILE *fp;
char fileName[] = "./main.cl";
char *source_str = new char[MAX_SOURCE_SIZE];
size_t source_size;
fp = fopen(fileName, "r");
if (!fp) {
fprintf(stderr, "Failed to load kernel.\n");
exit(-1);
}
source_size = fread(source_str, sizeof(char), MAX_SOURCE_SIZE, fp);
fclose(fp);
/* Create Kernel Program from the source */
cl_program program = clCreateProgramWithSource(context, 1,
(const char **)&source_str, (const size_t *)&source_size, &err);
/* Build Kernel Program */
const unsigned MAX_INFO_SIZE = 0x10000;
char info_buf[MAX_INFO_SIZE];
err = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
if (err != CL_SUCCESS)
{
fprintf(stderr, "clBuild failed:%d\n", err);
clGetProgramBuildInfo(program, device_id, CL_PROGRAM_BUILD_LOG, MAX_INFO_SIZE, info_buf, NULL);
fprintf(stderr, "\n%s\n", info_buf);
exit(1);
}
else{
clGetProgramBuildInfo(program, device_id, CL_PROGRAM_BUILD_LOG, MAX_INFO_SIZE, info_buf, NULL);
printf("Kernel Build Success\n%s\n", info_buf);
}
/* Create OpenCL Kernel */
cl_kernel kernel = clCreateKernel(program, "main", &err);
程序运行时通过 clBuildProgram() 函数编译内核,编译成功函数会返回 CL_SUCCESS;当编译出错,我们可以通过 clGetProgramBuildInfo() 获取错误信息,进而对内核函数进行修改。如下图,因为上述代码的存在,使得 少了个; 这种低级但不易被发现的问题能够快速定位。
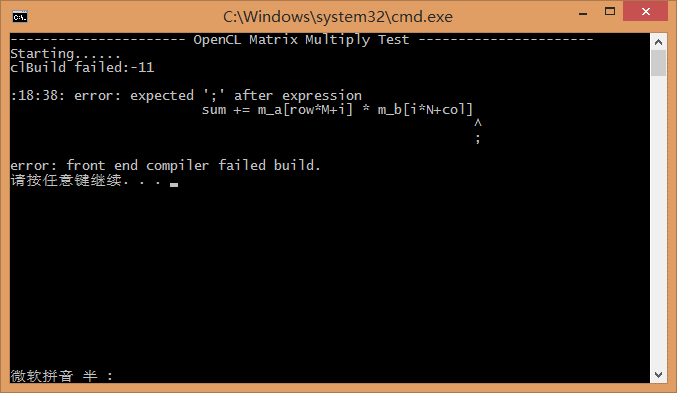
看到这里,是不是有种豁然开朗的感觉呢?不过还不够,建议您参考上述关于获取内核执行时间以及获取内核编译信息部分的代码,在自己的工程中也实现一下,看看能否顺利运行?运行效果如何?如果您没有现成的工程,可以使用上面提供的 VectorMultiply参考源代码(VS2013工程) 进行测试和修改。如果需要,也可以参考《win7 64位下VS2012搭建OpenCL开发环境(Intel显卡)/win8.1下VS2013亲测同样可行》,该教程可以指导您在win7或者win8.1下面搭建 VS 的 OpenCL 开发环境,有提供相关的 Intel OpenCL SDK。
参考书
点击获取所有参考书 访问密码 s6w9
- 《Introduction to OpenCL》 Nivida,2010 演讲课件
- 《Heterogeneous Computing with OpenCL》 (中英文版)
- 《OpenCL Programming Guide》 (中英文版)
- 《The OpenCL Specification》 (中英文版)